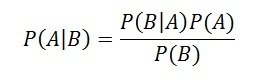Tabulation of data is the systematic presentation of classified data in the form of rows and columns. It is a method of arranging numerical information in a table to make it simple, concise, and easy to understand. After data has been classified, it is organized into tables so that comparisons, analysis, and interpretation can be carried out efficiently. Tabulation helps condense a large volume of information into a compact form and highlights important facts. It serves as a bridge between data collection and statistical analysis, making statistical information more meaningful and useful.
Definition
According to statistical experts, tabulation is the process of presenting classified data systematically in rows and columns to facilitate comparison, analysis, and interpretation.
Characteristics of Tabulation of Data
One of the most important characteristics of tabulation is the systematic presentation of data. Tabulation arranges information in rows and columns according to a logical pattern, making it easy to understand and analyze. Raw data collected from various sources is often scattered and difficult to interpret. Through tabulation, this information is organized into a structured format that highlights important facts. A systematic arrangement enables users to locate specific information quickly and reduces confusion. This characteristic improves the overall efficiency of data handling and provides a clear foundation for statistical analysis and business decision-making.
- Condenses Large Volumes of Data
Tabulation helps condense a large amount of information into a compact and manageable form. Instead of presenting lengthy descriptions or thousands of observations, data is summarized in tables. This reduction in size makes information easier to read and understand. Managers, researchers, and analysts can quickly grasp the essential facts without examining every individual detail. Condensation does not eliminate important information but presents it more efficiently. This characteristic is particularly useful in business and research where large datasets are common. Thus, tabulation simplifies the presentation of extensive information while retaining its significance.
A significant characteristic of tabulation is its ability to facilitate comparison. Data arranged in rows and columns allows users to compare different categories, groups, regions, or time periods easily. For example, a table showing annual sales figures enables quick comparison of performance across years. Such comparisons help identify differences, similarities, strengths, and weaknesses. They also assist managers in evaluating performance and making informed decisions. Without tabulation, comparing large amounts of raw data would be difficult and time-consuming. Therefore, facilitating comparison is one of the most valuable features of tabulated information.
- Enhances Clarity and Understanding
Tabulation improves the clarity and understanding of statistical information. Raw data often appears complex and confusing, especially when presented in large quantities. By arranging information systematically, tabulation makes data easier to comprehend. Clear headings, rows, and columns help readers interpret information accurately and quickly. This organized presentation reduces the possibility of misunderstanding and enhances communication. Managers, researchers, and policymakers can understand the information without requiring extensive explanations. Therefore, tabulation serves as an effective tool for presenting data in a clear, concise, and understandable manner.
- Supports Statistical Analysis
Tabulation provides a suitable foundation for statistical analysis. Before statistical measures such as averages, percentages, ratios, and correlations can be calculated, data must be organized systematically. Tabulated data enables researchers to perform these calculations accurately and efficiently. It also simplifies the identification of patterns and relationships within the data. Statistical techniques become more effective when applied to organized information. As a result, tabulation acts as a bridge between data collection and statistical interpretation. This characteristic makes tabulation an essential component of the statistical process in business and research studies.
Another important characteristic of tabulation is that it saves both time and space. Large amounts of information can be presented in a relatively small area through tables. Readers can quickly obtain the required information without reading lengthy reports or descriptions. This efficiency is particularly valuable in business environments where timely decisions are important. Tabulated data reduces the effort required for data presentation and analysis. By summarizing information effectively, tabulation helps organizations communicate key facts more efficiently. Consequently, it contributes to improved productivity and better utilization of resources.
- Reveals Trends and Relationships
Tabulation helps reveal trends, patterns, and relationships that may not be obvious in raw data. By arranging information in a structured format, it becomes easier to identify changes over time, differences between groups, and associations among variables. For example, a sales table may show a consistent increase in revenue over several years. Such observations support forecasting and strategic planning. Managers can use tabulated information to understand market behavior and business performance. Therefore, the ability to highlight trends and relationships is a key characteristic that enhances the analytical value of tabulation.
- Improves Accuracy and Reliability
Tabulation contributes to the accuracy and reliability of data presentation. The systematic arrangement of information reduces the likelihood of errors and omissions. Tables allow users to verify figures easily and identify inconsistencies if they occur. Proper tabulation also ensures that data is presented consistently, making interpretation more dependable. Accurate presentation is essential because business decisions often rely on statistical information. Errors in data presentation can lead to incorrect conclusions and poor decisions. Therefore, by promoting organized and precise data presentation, tabulation enhances the reliability and credibility of statistical information.
Principles of Tabulation
1. Principle of Simplicity
A table should be simple and easy to understand. Unnecessary details, complex arrangements, and excessive information should be avoided. The objective of tabulation is to simplify data presentation, not to make it more complicated. Simple tables enable readers to grasp information quickly without confusion. The language used in titles, headings, and notes should also be straightforward. Simplicity improves readability and facilitates analysis. Therefore, while preparing a table, only relevant information should be included, ensuring that the table remains clear, concise, and user-friendly for all readers.
2. Principle of Clarity
Clarity is an essential principle of tabulation. Every table should have a clear title, properly labeled rows and columns, and understandable figures. The information presented should not create ambiguity or confusion. Headings should accurately describe the contents of the table, and abbreviations should be avoided unless they are commonly understood. Clear presentation helps readers interpret the data correctly and draw meaningful conclusions. A table lacking clarity may lead to misunderstandings and incorrect analysis. Therefore, ensuring clarity in design and presentation is crucial for the effectiveness of tabulation.
3. Principle of Accuracy
Accuracy is one of the most important principles of tabulation. All figures included in a table must be correct and verified before presentation. Errors in calculations, classification, or data entry can lead to misleading conclusions and poor decision-making. Statistical tables should be prepared carefully to ensure that totals, percentages, and other numerical values are accurate. Consistency in units and measurements should also be maintained. Accurate tables enhance the reliability of information and increase confidence in the analysis. Thus, accuracy is essential for producing trustworthy and meaningful statistical tables.
4. Principle of Proper Title
Every table should have a suitable and self-explanatory title. The title should clearly indicate the subject matter, scope, and purpose of the table. A good title enables readers to understand the contents of the table without needing additional explanations. It should be brief yet comprehensive enough to convey the necessary information. The title is usually placed at the top of the table and serves as its identity. Proper titles improve communication and make statistical information easier to interpret. Therefore, selecting an appropriate title is a fundamental principle of tabulation.
5. Principle of Logical Arrangement
The data within a table should be arranged logically and systematically. Rows and columns should follow a meaningful order, such as alphabetical, chronological, geographical, or numerical arrangement. Logical organization helps readers locate information quickly and understand relationships among data items. Random placement of figures may create confusion and reduce the usefulness of the table. A logical arrangement enhances readability and facilitates comparison and analysis. Therefore, proper sequencing of data is essential for ensuring that a table effectively communicates statistical information to its users.
6. Principle of Comparability
A good table should facilitate easy comparison among different categories, groups, or periods. Similar items should be placed close to each other, and uniform units of measurement should be used throughout the table. Comparative data helps readers identify similarities, differences, and trends. For example, sales figures for multiple years should be presented in adjacent columns to allow direct comparison. The principle of comparability increases the analytical value of tabulated data and supports informed decision-making. Therefore, tables should be designed in a way that promotes meaningful and convenient comparisons.
7. Principle of Completeness
A table should contain all relevant information necessary for understanding the data. Incomplete tables may create confusion and limit the usefulness of the information presented. Important details such as units of measurement, totals, footnotes, and source references should be included wherever necessary. Completeness ensures that readers have access to all essential information needed for interpretation. However, completeness should not result in overcrowding the table with unnecessary details. A balance should be maintained between providing sufficient information and preserving simplicity. Thus, completeness is an important principle of effective tabulation.
8. Principle of Attractiveness
A table should be neat, well-organized, and visually appealing. Attractive presentation encourages readers to examine and understand the information more easily. Proper spacing, alignment, headings, and formatting contribute to the appearance of a table. A cluttered or poorly designed table may discourage readers and reduce the effectiveness of communication. While accuracy and clarity are essential, visual appeal also plays a role in improving readability. Therefore, statistical tables should be designed in a manner that is both functional and aesthetically pleasing, enhancing their overall usefulness and impact.
Parts of a Table
A statistical table is a sjhuystematic arrangement of data in rows and columns designed to present information clearly and concisely. It helps organize large amounts of data, making comparison, analysis, and interpretation easier. Every statistical table consists of several important parts, each serving a specific purpose. These components ensure that the table is complete, accurate, and easy to understand. Understanding the different parts of a table is essential for preparing and interpreting statistical information effectively.
1. Table Number
The table number is a unique identification number assigned to a table. It helps readers locate and refer to a particular table easily, especially in reports, books, research papers, and statistical publications containing multiple tables. Table numbers are usually placed at the top of the table before the title.
Importance
- Facilitates easy reference.
- Helps in indexing and organization.
- Avoids confusion when multiple tables are used.
Example: Sales Performance of XYZ Company During 2024
2. Title
The title is a brief statement that describes the contents of the table. It should clearly indicate what information is presented, including the subject, place, and time period whenever necessary. A good title should be concise, self-explanatory, and informative.
Importance:
- Provides an immediate understanding of the table.
- Defines the scope of the data.
- Helps readers interpret information correctly.
Example: Sales of Electronic Products in India During 2024
3. Headnote
A headnote is an explanatory note placed below the title and above the main body of the table. It provides additional information about units of measurement, definitions, or special conditions related to the data presented.
Importance:
- Clarifies the meaning of figures.
- Specifies units and measurements.
- Prevents misunderstanding of data.
4. Captions (Column Headings)
Captions are the headings placed at the top of columns. They indicate the nature of the information contained in each column and help readers understand the data presented.
Importance:
- Identifies column contents.
- Improves clarity and readability.
- Facilitates comparison among columns.
Example
| Year |
Sales (₹ Lakhs) |
Profit (₹ Lakhs) |
Here, Year, Sales, and Profit are captions.
5. Stubs (Row Headings)
Stubs are the headings placed at the left side of rows. They describe the categories or items represented in each row of the table.
Importance:
- Identifies row contents.
- Organizes data systematically.
- Makes interpretation easier.
Example
| Product |
Sales |
| Mobile Phones |
500 |
| Laptops |
300 |
Here, Mobile Phones and Laptops are listed under the stub column.
6. Body of the Table
The body is the main part of the table containing the actual statistical data. It consists of numerical values or information arranged at the intersection of rows and columns.
Importance:
- Contains the core information.
- Provides the basis for analysis and interpretation.
- Represents the results of classification and tabulation.
Example
| Product |
Sales (Units) |
| Mobile Phones |
1,500 |
| Laptops |
800 |
The figures 1,500 and 800 form the body of the table.
7. Footnote
A footnote is an explanatory remark placed below the table. It provides additional clarification about specific figures, symbols, abbreviations, or exceptional circumstances related to the data.
Importance:
- Explains special cases.
- Clarifies symbols and abbreviations.
- Enhances understanding of the table.
Example
Note: Sales figures exclude export transactions.
8. Source Note
The source note indicates the origin from which the data has been obtained. It is usually placed below the footnote at the bottom of the table.
Importance:
- Establishes authenticity and credibility.
- Enables verification of information.
- Acknowledges the original source.
Example
Source: Annual Report of XYZ Company, 2024.
Illustrative Table Showing All Parts
Sales Performance of XYZ Company During 2024
(Figures in ₹ Lakhs)
| Product Category |
Sales |
Profit |
| Mobile Phones |
500 |
120 |
| Laptops |
300 |
80 |
| Tablets |
200 |
50 |
Note: Figures exclude export sales.
Source: XYZ Company Annual Report, 2024.
Types of Tabulation with Examples
 by
by