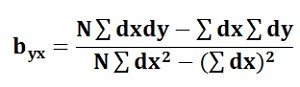Conditional Probability, Meaning, Definition, Characteristics, Applications, Advantages and Limitations
 by
by Conditional Probability refers to the probability of an event occurring given that another event has already occurred. It measures how the occurrence of one event affects the likelihood of another event. In many real-life situations, events are not independent, and the probability of one event depends on the outcome of another. Conditional probability helps analyze such relationships and provides a more accurate understanding of uncertain situations.
This concept is widely used in business, economics, finance, insurance, medicine, and statistics. It helps organizations make informed decisions by considering available information and understanding how different events are connected.
Definition
Conditional Probability is the probability of an event occurring under the condition that another related event has already taken place.
The probability of the occurrence of an event A given that an event B has already occurred is called the conditional probability of A given B:
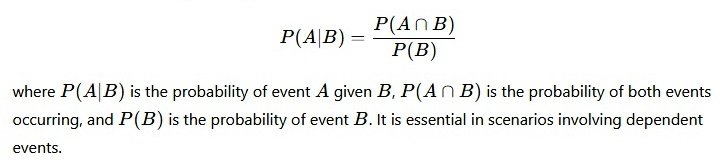
The same is explained in Figure 2.15 using the sample spaces related to the events A and B, assuming that there are few sample points common to these two events. Part 1 of the figure shows the total sample space related to the experiment as in the form of rectangle and the sample space related to the event A as a circle. Similarly part 2 of the figure shows the total sample space and the sample space related to event B. As explained earlier in conditional probability the total sample space is restrained to the sample space that is related to event B (which has already occurred). The same is shown in part 3 of Figure 2.15. Now the sample space for event A (B is the total sample space available) is nothing but the sample points related to event A and falling in the sample space. This is nothing but the intersection of the events A and B and is shown in part 3 of the figure as the hatched area.

Figure 2.15: Representation of conditional probability using the Venn diagrams
For example, there are 100 trips per day between two places X and Y. Out of these 100 trips 50 are made by car, 25 are made by bus and the other 25 are by local train. Probabilities associated to these modes are 0.5, 0.25, and 0.25, respectively. In transportation engineering both the bus and the local train are considered as public transport so the event space associated to this is the summation of the event spaces associated to bus and local train. Probability of choosing public transportation is 0.5. Now if one is interested in finding the probability of choosing bus given public transportation is chosen the conditional probability is useful in finding that.
Characteristics of Conditional Probability
- Depends on the Occurrence of Another Event
A key characteristic of conditional probability is that it depends on the occurrence of another event. Unlike simple probability, which measures the likelihood of an event independently, conditional probability considers additional information. The probability of an event changes when another related event has already occurred. For example, the probability of a customer purchasing a printer may increase if the customer has already purchased a laptop. This dependency makes conditional probability highly useful in analyzing real-world situations where events are interconnected and influence one another.
- Measures Relationships Between Events
Conditional probability helps measure and understand the relationship between two or more events. It shows how the occurrence of one event affects the likelihood of another event occurring. By analyzing these relationships, businesses and researchers can identify patterns and dependencies within data. For example, a retailer may study whether customers who buy one product are more likely to buy another. This characteristic makes conditional probability valuable in market research, risk assessment, and forecasting. It provides insights into event interactions that simple probability cannot capture effectively.
- Based on Joint Probability
Another important characteristic is that conditional probability relies on joint probability. To calculate conditional probability, the probability of both events occurring together must be known. Joint probability provides the foundation for determining how likely one event is when another has already occurred. This relationship ensures that conditional probability is mathematically consistent and accurate. By using joint probability, analysts can examine event dependencies in a systematic manner. This characteristic highlights the close connection between different probability concepts and their role in statistical analysis.
- Applicable to Dependent Events
Conditional probability is particularly useful when dealing with dependent events. Dependent events are events where the occurrence of one influences the probability of another. In many business and real-world situations, events are not independent. For example, customer purchasing decisions may depend on previous purchases or promotional offers. Conditional probability helps quantify these dependencies and provides more realistic probability estimates. This characteristic makes it an essential tool for understanding situations where outcomes are interconnected and cannot be analyzed accurately using independent probabilities alone.
- Provides Updated Probability Estimates
Conditional probability allows probabilities to be updated when new information becomes available. Instead of relying solely on initial estimates, it incorporates additional data to produce revised probability values. This characteristic is especially important in dynamic environments where circumstances change over time. For example, a bank may reassess the probability of loan repayment after receiving updated information about a customer’s financial status. By adjusting probabilities based on current information, conditional probability improves the accuracy and relevance of decision-making and forecasting processes.
- Supports Better Decision-Making
A significant characteristic of conditional probability is its ability to support informed decision-making. By considering specific conditions and relevant information, it provides more accurate estimates of future outcomes. Managers, investors, and policymakers use conditional probability to evaluate alternatives and assess risks. For example, a business may determine the likelihood of achieving sales targets under certain market conditions. This information enables decision-makers to choose strategies that maximize opportunities and minimize risks. Consequently, conditional probability plays an important role in effective planning and management.
- Forms the Foundation of Advanced Statistical Methods
Conditional probability serves as the basis for many advanced statistical and analytical techniques. Concepts such as Bayes’ Theorem, predictive modeling, machine learning, and statistical inference all rely on conditional probability principles. By understanding how probabilities change under specific conditions, analysts can develop sophisticated models for forecasting and decision support. This characteristic demonstrates the importance of conditional probability in both theoretical and applied statistics. Its role as a foundational concept makes it essential for advanced research and data analysis across numerous disciplines.
- Widely Applicable in Real-Life Situations
Conditional probability has broad applicability in business, finance, insurance, healthcare, engineering, and many other fields. Real-world events are often dependent on specific conditions, making conditional probability highly relevant. Businesses use it to analyze customer behavior, assess risks, and forecast demand. Insurance companies use it to estimate claim probabilities based on customer profiles. Financial institutions apply it in credit risk analysis and investment decisions. This widespread applicability demonstrates its practical value and importance. As a result, conditional probability is one of the most widely used concepts in probability and statistics.
Applications of Conditional Probability in Business