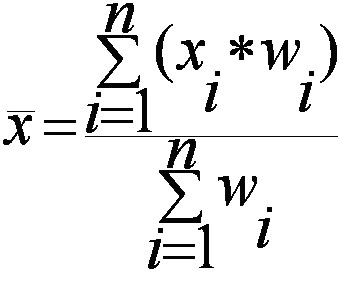Index Number, Features, Steps, Problems
 by
by Index Number is a statistical tool used to measure changes in economic variables over time, such as prices, quantities, or values. It expresses the relative change of a variable compared to a base period, usually set at 100. Index numbers help compare data across time, eliminating the effects of units or scales. They are widely used in economics and business to track inflation (e.g., Consumer Price Index), production, or cost changes. There are different types, including price index, quantity index, and value index. Methods of calculation include Laspeyres’, Paasche’s, and Fisher’s index. Index numbers simplify complex data, supporting decision-making and policy formulation in business and government.
Features of Index Numbers:
-
Statistical Device for Comparison
Index numbers serve as a powerful statistical tool to measure and compare relative changes in variables over time or location. They reduce complex and bulky data into a single, easily understandable figure. By converting raw data into percentage form based on a base year, they help highlight changes and trends in variables like prices, output, wages, etc. For instance, comparing consumer prices in different years becomes simpler and more effective using a price index. This comparative capability makes index numbers essential in economic and business decision-making.
-
Measure of Relative Change
Index numbers are primarily designed to show the relative change rather than absolute change. They express how much a variable has increased or decreased in percentage terms compared to a base period. For example, if a price index for a commodity is 125, it means there has been a 25% increase from the base year. This ability to convey relative movement enables users to quickly grasp the extent and direction of change, making index numbers a practical instrument for analyzing economic and financial performance.
-
Base Year Reference
Every index number uses a base year, which serves as the point of comparison. The value for the base year is always taken as 100, and all other values are expressed relative to it. Choosing an appropriate and normal base year is crucial, as it affects the accuracy and interpretation of the index. A well-chosen base year ensures that the index truly reflects meaningful changes over time. Without a base year, the concept of measuring “change” becomes invalid, as comparison needs a consistent starting point.
-
Simplifies Complex Data
Index numbers simplify the analysis of large datasets by converting varied data into a single number. Instead of tracking multiple prices or quantities individually, an index number consolidates the information into one comparable figure. This feature is especially useful in fields like economics, where analyzing movements in prices, costs, or production across different goods and services would otherwise be cumbersome. By providing a summarized measure, index numbers allow business managers, economists, and policymakers to quickly assess trends and make informed decisions.
-
Helps in Economic Analysis and Policy Making
Index numbers are essential tools in economic analysis and government policy formulation. They help track inflation, cost of living, industrial production, and other macroeconomic indicators. For example, the Consumer Price Index (CPI) is often used to adjust salaries and pensions to keep pace with inflation. Index numbers also guide central banks in framing monetary policy. By showing the direction and intensity of economic changes, they provide a factual basis for interventions, budgeting, and strategic planning, ensuring decisions are data-driven and aligned with current economic trends.
-
Various Types for Different Purposes
There are different kinds of index numbers, such as price index, quantity index, and value index, each serving specific needs. A Price Index tracks changes in the price level of goods and services, a Quantity Index measures changes in the physical quantity of goods, and a Value Index reflects changes in total monetary value. This classification makes index numbers versatile for business and economic use. Depending on the objective, businesses can choose the right type to measure trends in cost, output, or revenue over time.
Steps in the Construction of Price Index Numbers:
1. Define the Purpose and Scope
The first step is to clearly define the objective of the price index—whether it is to measure inflation, cost of living, wholesale prices, or retail prices. This helps determine the type of price index required. The scope includes deciding whether the index will cover all goods and services or only selected ones. A well-defined purpose ensures relevance, consistency, and applicability of the index in real-world decision-making. It also helps identify the target population or sector to which the index will apply.
2. Selection of the Base Year
A base year is the benchmark period against which changes in prices are measured. It is assigned an index value of 100. The base year should be a normal year, free from major economic fluctuations such as inflation, deflation, war, or natural disasters. A well-chosen base year ensures that the comparisons made over time are valid and meaningful. The base year must be recent enough to be relevant, yet stable enough to serve as a reliable point of reference for future comparisons.
3. Selection of Commodities
The selection of goods and services included in the index must reflect the consumption habits of the population or sector under study. The commodities should be representative, regularly used, and available in most markets. The number of items should be sufficient to provide accurate results but not too large to make data collection and computation difficult. For example, a Consumer Price Index may include food, clothing, housing, and transportation items that are commonly consumed by the average household.
4. Collection of Prices
Prices of the selected commodities must be collected for both the base year and the current year. The data should be obtained from reliable sources such as retail stores, wholesale markets, government publications, or official agencies. It is essential to ensure uniformity in the quality, quantity, and unit of measurement of the items while collecting prices. The method of price collection (monthly, quarterly, annually) should also be decided in advance. Accurate and consistent price data is crucial for the credibility of the index.
5. Selection of the Weighting System
Weights are assigned to commodities based on their relative importance or share in total consumption. Heavier weights are given to goods with larger expenditure shares. There are two main types of index numbers: unweighted (all items treated equally) and weighted (different weights for different items). Weighted indices provide more accurate results because they reflect real consumption patterns. The weights can be based on expenditure surveys or input-output data. Common weighting methods include Laspeyres, Paasche, and Fisher’s index formulas.
6. Choice of Formula for Index Calculation
Several formulas exist for calculating price index numbers, each with different assumptions and uses. The most common are:
-
Laspeyres’ Index: Uses base year quantities as weights.
-
Paasche’s Index: Uses current year quantities as weights.
-
Fisher’s Index: Geometric mean of Laspeyres and Paasche.
The choice depends on the data available and the intended use of the index. The selected formula must be consistent, logical, and easy to interpret. It should ideally satisfy the tests of a good index number.
7. Computation and Interpretation
Once the data is collected and the formula chosen, the index number is calculated. The resulting figure shows how much prices have increased or decreased relative to the base year. An index above 100 indicates a rise in prices; below 100 indicates a fall. After computation, the index should be analyzed and interpreted in light of the economic conditions. The final index number can then be published or used for policy decisions, wage adjustments, or business strategy formulation.
Problems in the Construction of Price Index Numbers:
-
Selection of Base Year
Choosing a suitable base year is a major problem. The base year must be a “normal” year—free from economic disruptions like war, recession, or natural disasters—to serve as a reliable point of comparison. However, what is considered normal can vary depending on economic conditions and regions. An inappropriate base year may distort the index and reduce its accuracy. Additionally, over time, the relevance of the base year may diminish, necessitating revisions to keep the index current and reflective of changing economic environments.
-
Selection of Commodities
Another difficulty is choosing the right basket of goods and services. The selected commodities must be representative of the consumption patterns of the target population, but consumer preferences and availability of goods change over time. Including too many items makes data collection complicated, while too few may lead to inaccurate representation. Additionally, new products may enter the market and old ones become obsolete, making it hard to maintain consistency. Thus, maintaining a relevant, updated, and balanced list of items is a persistent challenge.
-
Price Collection Issues
Accurate and consistent price data collection is a critical challenge. Prices may vary across locations, sellers, quality, and time, making it hard to ensure uniformity. Seasonal variations, local taxes, and discounts can also affect price levels. Collecting current and historical prices from reliable sources for numerous commodities and markets requires time, resources, and coordination. Errors, inconsistencies, or manipulation in data collection can result in misleading index numbers. Therefore, ensuring timely and credible price data is essential but often difficult in practice.
-
Weight Assignment Difficulty
Assigning appropriate weights to different commodities is a complex task. Weights are supposed to reflect the importance of each item in total consumption or expenditure, but getting this data involves conducting detailed consumer surveys or using outdated information. Consumption patterns also vary among income groups, regions, and over time, which further complicates weight assignment. Incorrect or outdated weights can lead to biased index numbers. Even when accurate weights are assigned initially, regular updates are required to reflect real-world consumption behavior.
-
Choice of Formula
There is no universally accepted formula for constructing index numbers. Different formulas (Laspeyres, Paasche, Fisher, etc.) yield different results even with the same data. Each formula has its own advantages and limitations. For example, Laspeyres’ index tends to overstate price rise, while Paasche’s may understate it. Choosing the right formula depends on the nature of data and the objective of the index, which can cause confusion. Moreover, some formulas are mathematically complex and difficult to apply, especially when resources or computational tools are limited.
-
Changing Consumption Patterns
Over time, consumers change their consumption habits due to income changes, tastes, technology, or availability of goods. This makes the original basket of commodities and assigned weights less relevant. For instance, the growing use of smartphones has replaced traditional phones and alarm clocks. If the index does not reflect such changes, it fails to represent current economic realities. Regular updates are needed, but frequent revisions may reduce comparability across time. Balancing accuracy and consistency is a persistent challenge in index number construction.