Scatter Plots, Meaning, Definition, Characteristics, Uses, Types, Steps, Applications, Advantages and Limitations
 by
by Scatter Plot is a graphical method used in statistics to study the relationship between two variables. It consists of a set of points plotted on a graph, where one variable is represented on the horizontal axis (X-axis) and the other on the vertical axis (Y-axis). Each point on the graph represents a pair of values.
Scatter plots help identify the direction, strength, and nature of the relationship between variables. They are widely used in business statistics, economics, marketing, finance, and research to analyze correlations and trends.
Definition of Scatter Plot
Scatter plot is a diagram that displays the relationship between two quantitative variables by plotting their paired observations as points on a coordinate plane.
Characteristics of Scatter Plots
- Displays Relationship Between Two Variables
A scatter plot is primarily used to show the relationship between two quantitative variables. One variable is plotted on the horizontal axis and the other on the vertical axis. Each point represents a pair of values. By observing the arrangement of points, analysts can determine whether a relationship exists between the variables. This characteristic makes scatter plots an effective tool for studying associations, trends, and patterns in business, economics, and research data.
- Uses Individual Data Points
In a scatter plot, every observation is represented by a separate point on the graph. Unlike grouped charts, scatter plots display individual data values without combining them into categories. This allows analysts to examine the exact distribution of observations. The use of individual points provides a detailed view of the dataset and helps identify variations among observations. Consequently, scatter plots offer a more accurate representation of relationships between variables.
- Indicates Direction of Correlation
One of the key characteristics of a scatter plot is its ability to show the direction of correlation. If the points move upward from left to right, the correlation is positive. If they move downward, the correlation is negative. When no pattern exists, there is no correlation. This visual representation helps managers and researchers quickly understand how changes in one variable affect another. Therefore, scatter plots are widely used in correlation analysis.
- Reveals Strength of Relationship
Scatter plots help determine the strength of the relationship between variables. When points are closely clustered around an imaginary line, the relationship is strong. When points are widely scattered, the relationship is weak. This characteristic enables analysts to assess the degree of association without performing complex calculations. By examining the concentration of points, businesses can evaluate the effectiveness of factors such as advertising, pricing, training, or production on desired outcomes.
- Easy to Construct and Interpret
Scatter plots are simple to create and easy to understand. They require only paired observations and a coordinate system for plotting. The graphical presentation makes relationships visible at a glance, even to individuals with limited statistical knowledge. This simplicity increases their popularity in business reports, presentations, and research studies. Because of their visual appeal and straightforward interpretation, scatter plots are widely used for preliminary data analysis and decision-making.
- Helps Identify Outliers
Another important characteristic of scatter plots is their ability to identify outliers. Outliers are observations that differ significantly from the general pattern of data. In a scatter plot, such values appear isolated from the majority of points. Detecting outliers is important because they may indicate errors, unusual events, or special circumstances requiring further investigation. This characteristic improves data quality and helps analysts avoid misleading conclusions during statistical analysis.
- Useful for Trend Analysis
Scatter plots are valuable tools for identifying trends and patterns in data. The overall arrangement of points reveals whether variables move together or in opposite directions. Businesses use scatter plots to analyze sales growth, advertising effectiveness, production efficiency, and customer behavior. Recognizing trends helps managers predict future outcomes and make informed decisions. Therefore, the ability to highlight trends is one of the most practical characteristics of scatter plots in business statistics.
- Provides Visual Representation of Correlation
Scatter plots offer a clear visual representation of correlation between variables. Instead of relying solely on numerical coefficients, analysts can observe the actual pattern formed by the data points. This graphical approach makes it easier to understand relationships and communicate findings to others. Visual representations are especially useful in business environments where quick interpretation is essential. As a result, scatter plots serve as an effective and widely accepted method for studying and presenting correlations.
Uses of Scatter Plots
- Studying Correlation Between Variables
One of the primary uses of scatter plots is to study the correlation between two variables. By plotting paired observations on a graph, analysts can determine whether the variables are positively related, negatively related, or unrelated. The pattern of points helps identify the direction and strength of the relationship. In business statistics, this is useful for understanding how one factor influences another. Scatter plots provide a simple and effective visual tool for analyzing correlations before applying more advanced statistical methods.
- Analyzing Sales and Advertising Relationships
Businesses often use scatter plots to examine the relationship between advertising expenditure and sales revenue. By plotting advertising costs against sales figures, managers can determine whether increased advertising leads to higher sales. The visual representation helps assess the effectiveness of marketing campaigns and promotional activities. If a strong positive relationship exists, the company may decide to invest more in advertising. Thus, scatter plots support marketing decisions and help businesses allocate resources more efficiently.
- Forecasting Business Trends
Scatter plots are useful for identifying trends that can assist in forecasting future business performance. By analyzing the pattern of data points, managers can estimate how changes in one variable may affect another. For example, a business may study the relationship between customer demand and seasonal factors. Understanding such trends enables organizations to prepare future plans, manage inventory, and allocate resources effectively. Therefore, scatter plots serve as valuable tools for forecasting and strategic business planning.
- Evaluating Production Efficiency
Manufacturing organizations use scatter plots to evaluate the relationship between production inputs and outputs. For example, labor hours may be plotted against units produced to determine whether increased effort leads to higher productivity. The resulting pattern helps managers identify efficiency levels and potential areas for improvement. By understanding these relationships, businesses can optimize resource utilization and reduce operational costs. Consequently, scatter plots contribute to improved production management and organizational performance.
- Identifying Outliers and Unusual Observations
Scatter plots are highly effective in detecting outliers and unusual observations within a dataset. Points that appear far from the general pattern indicate exceptional cases that may require further investigation. These outliers may result from measurement errors, unusual business events, or unique circumstances. Identifying such observations is important because they can influence statistical results and business decisions. Therefore, scatter plots help improve data quality and ensure more reliable analysis by highlighting irregularities in the dataset.
- Supporting Financial Analysis
Financial analysts use scatter plots to study relationships between financial variables such as risk and return, income and expenditure, or investment and profit. The graphical representation helps identify patterns that may influence financial decision-making. Investors can assess whether higher risk is associated with higher returns, while businesses can evaluate the impact of investment strategies. By providing a visual understanding of financial relationships, scatter plots assist in planning, budgeting, and risk management activities.
- Assisting Market Research
In market research, scatter plots help analyze consumer behavior and purchasing patterns. Businesses can study relationships between factors such as customer income and spending, age and product preference, or price and demand. The resulting patterns provide valuable insights into market trends and customer needs. These insights help organizations design effective marketing strategies, improve product offerings, and target specific customer segments. Therefore, scatter plots are important tools for understanding market dynamics and enhancing business competitiveness.
- Improving Decision-Making
Scatter plots support managerial decision-making by presenting complex data relationships in a simple visual format. Decision-makers can quickly observe trends, correlations, and unusual patterns without relying solely on numerical calculations. This visual clarity helps managers evaluate alternatives and choose appropriate courses of action. Whether analyzing sales performance, production efficiency, customer behavior, or financial outcomes, scatter plots provide useful information for informed decisions. Consequently, they play an important role in business analysis, planning, and organizational management.
Types of Scatter Plots
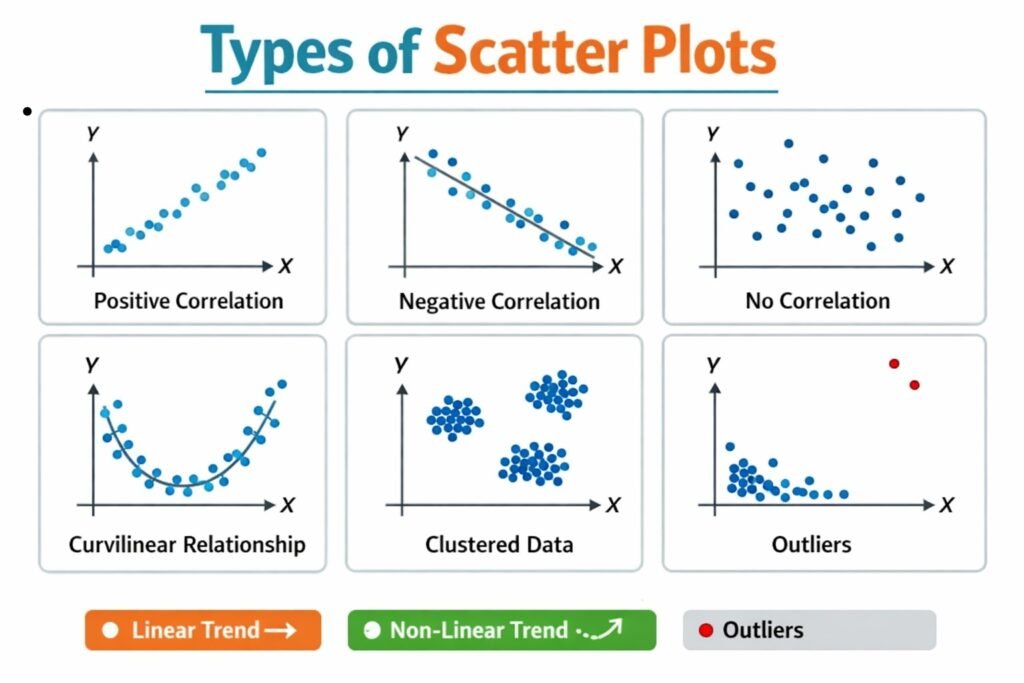
1. Positive Scatter Plot (Positive Correlation)
Positive Scatter Plot shows a positive relationship between two variables. In this type of scatter plot, as the value of one variable increases, the value of the other variable also increases. The plotted points tend to move upward from the lower-left corner to the upper-right corner of the graph. The closer the points are to an imaginary straight line, the stronger the positive correlation. Positive scatter plots are commonly found in business situations where variables move in the same direction. They help managers understand how increases in one factor may lead to increases in another factor.
Example: The relationship between advertising expenditure and sales revenue is usually positive. As advertising expenses increase, sales generally increase.
Characteristics
- Upward trend of points.
- Variables move in the same direction.
- Indicates direct relationship.
- Can be strong or weak positive correlation.
- Useful for forecasting growth.
2. Negative Scatter Plot (Negative Correlation)
Negative Scatter Plot shows a negative relationship between two variables. In this type of plot, as one variable increases, the other decreases. The points move downward from the upper-left corner to the lower-right corner of the graph. The closer the points are to a straight descending line, the stronger the negative correlation. Negative scatter plots are useful in identifying inverse relationships between variables. Businesses often use them to study factors that move in opposite directions and to understand the impact of one variable on another.
Example: The relationship between product price and quantity demanded is generally negative. When prices increase, demand usually decreases.
Characteristics
- Downward trend of points.
- Variables move in opposite directions.
- Indicates inverse relationship.
- May be strong or weak negative correlation.
- Useful in demand and pricing analysis.
3. Zero Scatter Plot (No Correlation)
Zero Scatter Plot indicates that there is no relationship between the two variables. The points are scattered randomly across the graph without forming any recognizable pattern. Changes in one variable do not systematically affect the other variable. Since there is no correlation, the values of one variable cannot be used to predict the values of the other. This type of scatter plot is important because it helps analysts identify situations where variables are unrelated. Recognizing the absence of a relationship prevents incorrect assumptions and improves the accuracy of business analysis.
Example: There is generally no relationship between a person’s shoe size and intelligence level.
Characteristics
- Random distribution of points.
- No upward or downward trend.
- Variables are unrelated.
- Correlation is approximately zero.
- Limited forecasting value.
4. Perfect Positive Scatter Plot
Perfect Positive Scatter Plot occurs when all points lie exactly on a straight line that slopes upward from left to right. This indicates a perfect positive correlation, meaning that every increase in one variable is accompanied by a proportional increase in the other variable. The coefficient of correlation in this case is +1. Although perfect positive relationships are rare in real-life business situations, they provide a theoretical model for understanding strong direct relationships. Such plots demonstrate complete consistency between the variables.
Example: Temperature measured in Celsius and Fahrenheit has a perfect positive relationship.
Characteristics
- All points lie on a straight upward line.
- Correlation coefficient = +1.
- Perfect direct relationship.
- No deviation from the trend.
- Rare in practical business data.
5. Perfect Negative Scatter Plot
Perfect Negative Scatter Plot occurs when all points lie exactly on a straight line sloping downward from left to right. This indicates a perfect negative correlation where every increase in one variable results in a proportional decrease in the other variable. The coefficient of correlation is –1. Like perfect positive correlation, perfect negative relationships are uncommon in business data. However, they are important in statistical theory because they represent the strongest possible inverse relationship between variables.
Example: Distance traveled and fuel remaining in a vehicle under constant conditions may show a nearly perfect negative relationship.
Characteristics
- All points lie on a straight downward line.
- Correlation coefficient = –1.
- Perfect inverse relationship.
- No variation from the trend.
- Useful for theoretical analysis.
6. Curvilinear Scatter Plot
Curvilinear Scatter Plot shows a relationship between variables that follows a curve rather than a straight line. In this type of scatter plot, the variables are related, but the rate of change is not constant. As one variable changes, the other may increase or decrease at varying rates. Curvilinear relationships are common in economics and business where real-world variables often behave in complex ways. This type of scatter plot helps analysts identify nonlinear relationships that cannot be explained by simple correlation.
Example: The relationship between employee experience and productivity may initially increase rapidly and then level off over time.
Characteristics
- Points form a curved pattern.
- Indicates nonlinear relationship.
- Variables are related but not linearly.
- Common in economic and business data.
- Useful for advanced statistical analysis.