Quantitative Research
 by
by Quantitative research methods are those methods where a systematic approach is used to collect quantifiable of data by performing computational, mathematical, or statistical techniques. The data collected through quantitative research methods are usually in numerical form.
The proper outcome can be deduced by analyzing the data in a systematic form. The results obtained through quantitative research methods are statistical, logical, and unbiased.
These research methods are applied to a group of the population, which represents the entire population.
Methods like survey research, cross-sectional surveys, longitudinal surveys, correlational research, causal-comparative research, experimental research, are primary data collection methods in quantitative research methods whereas the data collected from methods such as educational institutions, public libraries, data available on internet, government and non-government resources, and commercial information resources, etc. are the secondary data collection methods in quantitative research methods. Click here to learn more about quantitative research methods.
Primary Quantitative Research Methods
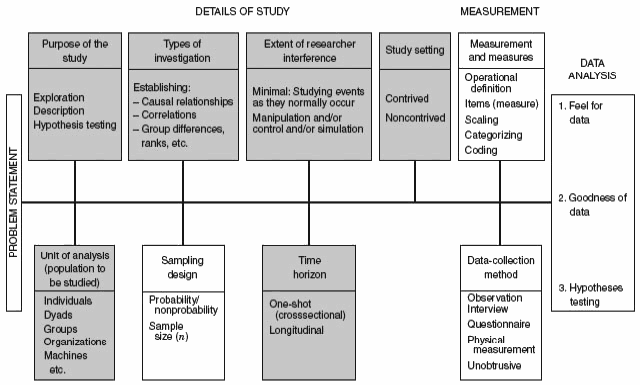
There are four different types of quantitative research methods:
Primary quantitative research is the most widely used method of conducting market research. The distinct feature of primary research is that the researcher focuses on collecting data directly rather than depending on data collected from previously done research. Primary quantitative research can be broken down into three further distinctive tracks, as well as the process flow. They are:
A. Techniques and Types of Studies
There are multiple types of primary quantitative research. They can be distinguished into the four following distinctive methods, which are:
- Survey Research:
Survey Research is the most fundamental tool for all quantitative research methodologies and studies. Surveys used to ask questions to a sample of respondents, using various types such as online polls, online surveys, paper questionnaires, web-intercept surveys, etc. Every small and big organization intends to understand what their customers think about their products and services, how well are new features faring in the market and other such details.
By conducting survey research, an organization can ask multiple survey questions, collect data from a pool of customers, and analyze this collected data to produce numerical results. It is the first step towards collecting data for any research.
This type of research can be conducted with a specific target audience group and also can be conducted across multiple groups along with comparative analysis. A prerequisite for this type of research is that the sample of respondents must have randomly selected members. This way, a researcher can easily maintain the accuracy of the obtained results as a huge variety of respondents will be addressed using random selection. Traditionally, survey research was conducted face-to-face or via phone calls but with the progress made by online mediums such as email or social media, survey research has spread to online mediums as well.
Traditionally, survey research was conducted face-to-face or via phone calls but with the progress made by online mediums such as email or social media, survey research has spread to online mediums as well.
There are two types of surveys, either of which can be chosen based on the time in-hand and the kind of data required:
Cross-sectional surveys: Cross-sectional surveys are observational surveys conducted in situations where the researcher intends to collect data from a sample of the target population at a given point in time. Researchers can evaluate various variables at a particular time. Data gathered using this type of survey is from people who depict similarity in all variables except the variables which is considered for research. Throughout the survey, this one variable will stay constant.
- Cross-sectional surveys are popular with retail, SMEs, healthcare industries. Information is garnered without modifying any parameters in the variable ecosystem.
- Using cross-sectional survey research method, multiple samples can be analyzed and compared.
- Multiple variables can be evaluated using this type of survey research.
- The only disadvantage of cross-sectional surveys is that the cause-effect relationship of variables cannot be established as it usually evaluates variables at a particular time and not across a continuous time frame.
Longitudinal surveys: Longitudinal surveys are also observational surveys but, unlike cross-sectional surveys, longitudinal surveys are conducted across various time durations to observe a change in respondent behavior and thought-processes. This time can be days, months, years, or even decades. For instance, a researcher planning to analyze the change in buying habits of teenagers over 5 years will conduct longitudinal surveys.
- In cross-sectional surveys, the same variables were evaluated at a given point in time, and in longitudinal surveys, different variables can be analyzed at different intervals of time.
- Longitudinal surveys are extensively used in the field of medicine and applied sciences. Apart from these two fields, they are also used to observe a change in the market trend, analyze customer satisfaction, or gain feedback on products/services.
- In situations where the sequence of events is highly essential, longitudinal surveys are used.
- Researchers say that when there are research subjects that need to be thoroughly inspected before concluding, they rely on longitudinal surveys.
- Correlational Research:
A comparison between two entities is invariable. Correlation research is conducted to establish a relationship between two closely-knit entities and how one impacts the other and what are the changes that are eventually observed. This research method is carried out to give value to naturally occurring relationships, and a minimum of two different groups are required to conduct this quantitative research method successfully. Without assuming various aspects, a relationship between two groups or entities must be established.
Researchers use this quantitative research method to correlate two or more variables using mathematical analysis methods. Patterns, relationships, and trends between variables are concluded as they exist in their original set up. The impact of one of these variables on the other is observed along with how it changes the relationship between the two variables. Researchers tend to manipulate one of the variables to attain the desired results.
Ideally, it is advised not to make conclusions merely based on correlational research. This is because it is not mandatory that if two variables are in sync that they are interrelated.
Example of Correlational Research Questions:
-
- The relationship between stress and depression.
- The equation between fame and money.
- The relation between activities in a third-grade class and its students.
- Causal-Comparative Research:
This research method mainly depends on the factor of comparison. Also called the quasi-experimental research, this quantitative research method is used by researchers to conclude cause-effect equation between two or more variables, where one variable is dependent on the other independent variable. The independent variable is established but not manipulated, and its impact on the dependent variable is observed. These variables or groups must be formed as they exist in the natural set up. As the dependent and independent variables will always exist in a group, it is advised that the conclusions are carefully established by keeping all the factors in mind.
Causal-comparative research is not restricted to the statistical analysis of two variables but extends to analyzing how various variables or groups change under the influence of the same changes. This research is conducted irrespective of the type of relation that exists between two or more variables. Statistical analysis is used to distinctly present the outcome of obtained using this quantitative research method.
Example of Causal-Comparative Research Questions:
- The impact of drugs on a teenager.
- The effect of good education on a freshman.
- The effect of substantial food provision in the villages of Africa.
- Experimental Research: Also known as true experimentation, this research method is reliant on a theory. Experimental research, as the name suggests, is usually based on one or more theories. This theory has not been proven in the past and is merely a supposition. In experimental research, an analysis is done around proving or disproving the statement. This research method is used in natural sciences.
There can be multiple theories in experimental research. A theory is a statement that can be verified or refuted.
After establishing the statement, efforts are made to understand whether it is valid or invalid. This type of quantitative research method is mainly used in natural or social sciences as there are various statements which need to be proved right or wrong.
- Traditional research methods are more effective than modern techniques.
- Systematic teaching schedules help children who find it hard to cope up with the course.
- It is a boon to have responsible nursing staff for ailing parents.