Law of Variable Proportions occupies an important place in economic theory. This law is also known as Law of Proportionality.
Keeping other factors fixed, the law explains the production function with one factor variable. In the short run when output of a commodity is sought to be increased, the law of variable proportions comes into operation.
Therefore, when the number of one factor is increased or decreased, while other factors are constant, the proportion between the factors is altered. For instance, there are two factors of production viz., land and labour.
Land is a fixed factor whereas labour is a variable factor. Now, suppose we have a land measuring 5 hectares. We grow wheat on it with the help of variable factor i.e., labour. Accordingly, the proportion between land and labour will be 1: 5. If the number of laborers is increased to 2, the new proportion between labour and land will be 2: 5. Due to change in the proportion of factors there will also emerge a change in total output at different rates. This tendency in the theory of production called the Law of Variable Proportion.
Definitions
“As the proportion of the factor in a combination of factors is increased after a point, first the marginal and then the average product of that factor will diminish.” – Benham
“An increase in some inputs relative to other fixed inputs will in a given state of technology cause output to increase, but after a point the extra output resulting from the same additions of extra inputs will become less and less.” – Samuelson
“The law of variable proportion states that if the inputs of one resource is increased by equal increment per unit of time while the inputs of other resources are held constant, total output will increase, but beyond some point the resulting output increases will become smaller and smaller.” – Leftwitch
Assumptions
Law of variable proportions is based on following assumptions:
(i) Constant Technology
The state of technology is assumed to be given and constant. If there is an improvement in technology the production function will move upward.
(ii) Factor Proportions are Variable
The law assumes that factor proportions are variable. If factors of production are to be combined in a fixed proportion, the law has no validity.
(iii) Homogeneous Factor Units
The units of variable factor are homogeneous. Each unit is identical in quality and amount with every other unit.
(iv) Short-Run
The law operates in the short-run when it is not possible to vary all factor inputs.
Explanation of the Law
In order to understand the law of variable proportions we take the example of agriculture. Suppose land and labour are the only two factors of production.
By keeping land as a fixed factor, the production of variable factor i.e., labour can be shown with the help of the following table:

From the table 1 it is clear that there are three stages of the law of variable proportion. In the first stage average production increases as there are more and more doses of labour and capital employed with fixed factors (land). We see that total product, average product, and marginal product increases but average product and marginal product increases up to 40 units. Later on, both start decreasing because proportion of workers to land was sufficient and land is not properly used. This is the end of the first stage.
The second stage starts from where the first stage ends or where AP=MP. In this stage, average product and marginal product start falling. We should note that marginal product falls at a faster rate than the average product. Here, total product increases at a diminishing rate. It is also maximum at 70 units of labour where marginal product becomes zero while average product is never zero or negative.
The third stage begins where second stage ends. This starts from 8th unit. Here, marginal product is negative and total product falls but average product is still positive. At this stage, any additional dose leads to positive nuisance because additional dose leads to negative marginal product.
Graphic Presentation
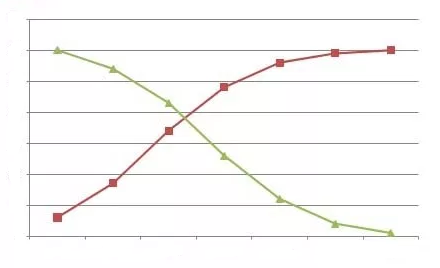
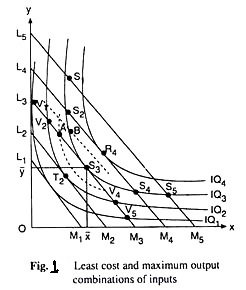
In fig. 1, on OX axis, we have measured number of labourers while quantity of product is shown on OY axis. TP is total product curve. Up to point ‘E’, total product is increasing at increasing rate. Between points E and G it is increasing at the decreasing rate. Here marginal product has started falling. At point ‘G’ i.e., when 7 units of labourers are employed, total product is maximum while, marginal product is zero. Thereafter, it begins to diminish corresponding to negative marginal product. In the lower part of the figure MP is marginal product curve.
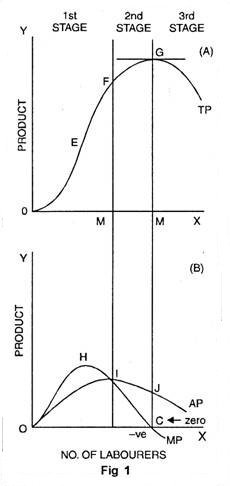
Up to point ‘H’ marginal product increases. At point ‘H’, i.e., when 3 units of labourers are employed, it is maximum. After that, marginal product begins to decrease. Before point ‘I’ marginal product becomes zero at point C and it turns negative. AP curve represents average product. Before point ‘I’, average product is less than marginal product. At point ‘I’ average product is maximum. Up to point T, average product increases but after that it starts to diminish.
Three Stages of the Law
- First Stage
First stage starts from point ‘O’ and ends up to point F. At point F average product is maximum and is equal to marginal product. In this stage, total product increases initially at increasing rate up to point E. between ‘E’ and ‘F’ it increases at diminishing rate. Similarly marginal product also increases initially and reaches its maximum at point ‘H’. Later on, it begins to diminish and becomes equal to average product at point T. In this stage, marginal product exceeds average product (MP > AP).
- Second Stage
It begins from the point F. In this stage, total product increases at diminishing rate and is at its maximum at point ‘G’ correspondingly marginal product diminishes rapidly and becomes ‘zero’ at point ‘C’. Average product is maximum at point ‘I’ and thereafter it begins to decrease. In this stage, marginal product is less than average product (MP < AP).
- Third Stage
This stage begins beyond point ‘G’. Here total product starts diminishing. Average product also declines. Marginal product turns negative. Law of diminishing returns firmly manifests itself. In this stage, no firm will produce anything. This happens because marginal product of the labour becomes negative. The employer will suffer losses by employing more units of labourers. However, of the three stages, a firm will like to produce up to any given point in the second stage only.

In Which Stage Rational Decision is Possible
To make the things simple, let us suppose that, a is variable factor and b is the fixed factor. And a1, a2 , a3….are units of a and b1 b2b3…… are unit of b.
Stage I is characterized by increasing AP, so that the total product must also be increasing. This means that the efficiency of the variable factor of production is increasing i.e., output per unit of a is increasing. The efficiency of b, the fixed factor, is also increasing, since the total product with b1 is increasing.
The stage II is characterized by decreasing AP and a decreasing MP, but with MP not negative. Thus, the efficiency of the variable factor is falling, while the efficiency of b, the fixed factor, is increasing, since the TP with b1 continues to increase.
Finally, stage III is characterized by falling AP and MP, and further by negative MP. Thus, the efficiency of both the fixed and variable factor is decreasing.
Rational Decision
Stage II becomes the relevant and important stage of production. Production will not take place in either of the other two stages. It means production will not take place in stage III and stage I. Thus, a rational producer will operate in stage II.
Suppose b were a free resource; i.e., it commanded no price. An entrepreneur would want to achieve the greatest efficiency possible from the factor for which he is paying, i.e., from factor a. Thus, he would want to produce where AP is maximum or at the boundary between stage I and II.
If on the other hand, a were the free resource, then he would want to employ b to its most efficient point; this is the boundary between stage II and III.
Obviously, if both resources commanded a price, he would produce somewhere in stage II. At what place in this stage production takes place would depend upon the relative prices of a and b.
Condition or Causes of Applicability
There are many causes which are responsible for the application of the law of variable proportions.
They are as follows:
- Under Utilization of Fixed Factor
In initial stage of production, fixed factors of production like land or machine, is under-utilized. More units of variable factor, like labour, are needed for its proper utilization. As a result of employment of additional units of variable factors there is proper utilization of fixed factor. In short, increasing returns to a factor begins to manifest itself in the first stage.
- Fixed Factors of Production
The foremost cause of the operation of this law is that some of the factors of production are fixed during the short period. When the fixed factor is used with variable factor, then its ratio compared to variable factor falls. Production is the result of the co-operation of all factors. When an additional unit of a variable factor has to produce with the help of relatively fixed factor, then the marginal return of variable factor begins to decline.
- Optimum Production
After making the optimum use of a fixed factor, then the marginal return of such variable factor begins to diminish. The simple reason is that after the optimum use, the ratio of fixed and variable factors become defective. Let us suppose a machine is a fixed factor of production. It is put to optimum use when 4 labourers are employed on it. If 5 labourers are put on it, then total production increases very little and the marginal product diminishes.
- Imperfect Substitutes
Mrs. Joan Robinson has put the argument that imperfect substitution of factors is mainly responsible for the operation of the law of diminishing returns. One factor cannot be used in place of the other factor. After optimum use of fixed factors, variable factors are increased and the amount of fixed factor could be increased by its substitutes.
Such a substitution would increase the production in the same proportion as earlier. But in real practice factors are imperfect substitutes. However, after the optimum use of a fixed factor, it cannot be substituted by another factor.
Applicability of the Law of Variable Proportions:
The law of variable proportions is universal as it applies to all fields of production. This law applies to any field of production where some factors are fixed and others are variable. That is why it is called the law of universal application.
The main cause of application of this law is the fixity of any one factor. Land, mines, fisheries, and house building etc. are not the only examples of fixed factors. Machines, raw materials may also become fixed in the short period. Therefore, this law holds good in all activities of production etc. agriculture, mining, manufacturing industries.
- Application to Agriculture
With a view of raising agricultural production, labour and capital can be increased to any extent but not the land, being fixed factor. Thus when more and more units of variable factors like labour and capital are applied to a fixed factor then their marginal product starts to diminish and this law becomes operative.
- Application to Industries
In order to increase production of manufactured goods, factors of production has to be increased. It can be increased as desired for a long period, being variable factors. Thus, law of increasing returns operates in industries for a long period. But, this situation arises when additional units of labour, capital and enterprise are of inferior quality or are available at higher cost.
As a result, after a point, marginal product increases less proportionately than increase in the units of labour and capital. In this way, the law is equally valid in industries.
Postponement of the Law
The postponement of the law of variable proportions is possible under following conditions:
(i) Improvement in Technique of Production
The operation of the law can be postponed in case variable factors techniques of production are improved.
(ii) Perfect Substitute
The law of variable proportion can also be postponed in case factors of production are made perfect substitutes i.e., when one factor can be substituted for the other.
 by
by