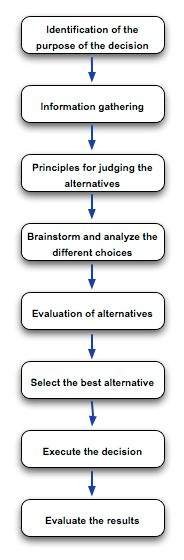
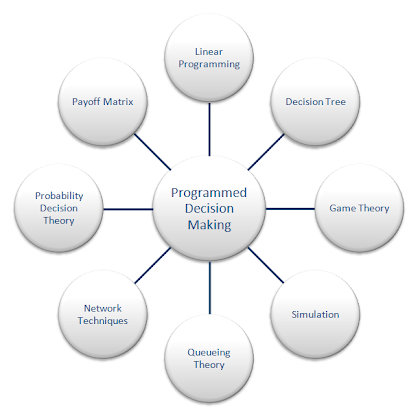
Decision making can be defined as selecting between alternative courses of action. Management decision making concerns the choices faced by managers within their duties in the organization. Making decisions is an important aspect of planning. Decision making can also be classified into three categories based on the level at which they occur.
Strategic Decisions: These decisions establish the strategies and objectives of the organization. These types of decisions generally occur at the highest levels of organizational management.
Tactical Decisions: Tactical decisions concern the tactics used to accomplish the organizational objectives. Tactical decisions are primarily made by middle and front-line managers.
Operational Decisions: Operational decisions concern the methods for carrying out the organizations delivery of value to customers. Operational decisions are primarily made by middle and front-line managers.
Decisions can be categorized based on the capacity of those making the decision.
Personal Decisions: Personal decisions are those primarily affecting the individual though the decision may ultimately have an effect on the organization as a result of its effect on the individual. These types of decisions are not made within a professional capacity. These decisions are generally not delegated to others.
Organizational Decisions: An organizational decision is one that relates or affects the organization. It is generally made by a manager or employee within their official capacity. These decisions are often delegated to others.
Strategies:
Marginal Analysis
Marginal analysis helps organizations allocate resources to increase profitability and benefits and reduce costs. An example from indeed.com is if a company has the budget to hire an employee, a marginal analysis may show that hiring that person provides a net marginal benefit because the ability to produce more products outweighs the increase in labor costs.
SWOT Diagram
This tool helps a manager study a situation in four quadrants:
- Strengths: Where does the organization excel compared to its competition? Consider the internal and external strengths.
- Weaknesses: What could the organization improve?
- Opportunities: How can the organization leverage its strengths to create new avenues for success.
- Threats: Determine what obstacles prevent the organization from achieving its goals.
Decision Matrix
A decision matrix can provide clarity when dealing with different choices and variables. It is like a pros/cons list, but decision-makers can place a level of importance on each factor. According to Dashboards, to build a decision matrix:
- List your decision alternatives as rows
- List relevant factors as columns
- Establish a consistent scale to assess the value of each combination of alternatives and factors
- Determine how important each factor is in choosing a final decision and assign weights accordingly
- Multiply your original ratings by the weighted rankings
- Add up the factors under each decision alternative
- The highest-scoring option wins
Pareto Analysis
The Pareto Principle helps identify changes that will be the most effective for an organization. It’s based on the principle that 20 percent of factors frequently contribute to 80 percent of the organization’s growth. For example, suppose 80 percent of an organization’s sales came from 20 percent of its customers. A business can use the Pareto Principle by identifying the characteristics of that 20 percent customer group and finding more like them. By identifying which small changes have the most significant impact, an organization can better prioritize its decisions and energies.
Steps:
Make long-term goals and use them to measure your decisions.
All too often, organizations find themselves endlessly running around in pursuit of short-term goals. Money that has been committed to a year-long project gets overrun or set off because flashy or short-term priorities arise and resources are redirected. As a result, you typically end up with an awful lot of confusion and a lack of overall progress.
To avoid this problem, nail down your high-priority, long-term goals from the outset. Then as your organization makes decisions, ask yourself whether what you’re doing aligns with those goals. This should be a constant process, returning again and again to check your organizational activity against your goals.
When you apply this method successfully, you will engage more reliably in short-term projects that support your long-term goals. Over time, this will push your organization forward.
Align your goals with your core values
Ideally, these should flow from your organization’s mission and core values. Your organization’s goals may evolve over time, but its values should be much less mutable.
Your organizational values confer a coherent sense of identity and continuity to your organization. They should be clearly understood and agreed upon by your decision-makers. As you evaluate your goals, make sure that they are aligned with your core values.
Assess (and reassess) spending
One way to evaluate your priorities as they are being realized today is to take a look at your spending. Often, you may think you’re prioritizing a particular goal or effort, while your budget tells a different story.
Make sure your organizational spending reflects your identified priorities. If not, you need to take a second look. And as with any such check-in, it’s essential to make this a regular assessment to continuously verify that you’re on track.
Understand the impacts of your decisions.
Some decisions may be discrete and routine, having neat boundaries and only significantly impacting the matter directly at hand. But more often, organizational decisions may have wide-ranging consequences, especially if they will touch on policy or processes.
As your organization considers varying possibilities, make sure to weight second and third-order effects. These consequences can provide crucial context for the decision at hand.
Remember your personnel.
Organizations tend to depend on the quality of their employees to succeed. If your decisions make it difficult for your employees to be productive in their work environment, it will damage your prospects for long-term success even if your decisions appear to advance a short-term goal.
Evaluate the effect your decisions will have on your employees’ ability to perform their jobs and factor this component into your decisions accordingly.
The most effective decision-making should lead to improved work toward your long-term goals, which should be driven by core values. You should constantly reevaluate your spending and assess likely consequences of your actions. If you follow these steps thoroughly, you will have assembled a framework for successful organizational decision-making.
Advantages of Decision Making
Increase People’s Participation
Decision making in the organisation is done by a group of peoples working in the organisation. It is not carried out by a single individual rather than by a group of people. Each people actively participates in decision making of the organisation. They are free to present their creative ideas without any boundations.
Also, none of them is individually criticized for any failure but the whole group is responsible to handle. This increases the participation level of different people in the organisation.
Gives More Information
Good decision-making process acquires enough information before taking any action. In decision making, there is a large number of peoples involved. It is undertaken by the whole group rather than by a single individual. Each person gives his perspective to handle a particular situation.
They all represent there facts and figures according to their skill. This generates enough information which can be used for better understanding of the situation. This helps managers in taking corrective decisions.
Provide More Alternatives
Companies are able to get different alternatives for a particular situation through group decision making. There are different people working as a group for proper decisions. Each person looks differently to a particular problem.
They give their own perspectives and ideas for it. This way there are different options available to choose. All the alternatives are properly analysed in light of handling situation. The best one is chosen to arrive at a better result.
Improves the Degree of Acceptance and Commitment
Companies always face the chances of conflict among its staff working in the organisation. Through group decision making each person gets equal right to share his views and ideas.
Here decisions are not imposed on the peoples but are created with their participation. It develops a sense of loyalty and belongingness among people towards the business. They easily accept the decisions taken and are committed to their roles.
Helps In Strengthening the Organisation
It helps in improving the strength of the organisation. Decision making provides a platform to each individual working in an organisation to equally represent their ideas. Everybody gets an equal right to take part in managing the organisation.
It develops a sense of cooperation and unity among individuals working there. They all come together and work towards the accomplishment of the company’s goals. This increases the overall productivity of the organisation and strengthens its overall structure.
Improves the Quality of Decisions
Decision making helps in taking quality decisions at the right time. There are different experts engaged by organisations in their decision-making group. These peoples have through knowledge and creative thinking.
They analyse each and every aspect of every alternative available to them for handling situations. Best among the different alternatives available is chosen. It enables in quality decision making which helps in easy attainment of objectives.
Limitations:
Consultation ambiguity: This can be a scenario where a group of employees all feel like they have a vote in a decision or when a manager asks for input but doesn’t consider a group’s views. It’s important for a manager to solicit feedback but to make sure that contributors understand it’s the manager’s final decision.
Avoiding discomfort: Sound management decision making requires leaders who do not confuse their need for comfort with making the best decision. Some of the most effective decisions involve a degree of discomfort for the manager.
Appearing indecisive: Sometimes, a systematic decision making process has a downside. Being too rigorous in evaluating every possible angle can draw out the process and open the risk of appearing indecisive. Keep stakeholders informed about the timeline for a decision.
Blind spots: People have particular perspectives and ways of thinking that can create blind spots, which may be important for an effective decision but cannot be readily apparent. It can be helpful to seek input from trusted colleagues to provide a different perspective.
Groupthink: This occurs when a group’s members want to minimize conflict and reach a comfortable decision at the expense of a critical evaluation of other ideas and viewpoints. It’s important to explore alternatives a group may not have considered.
 by
by