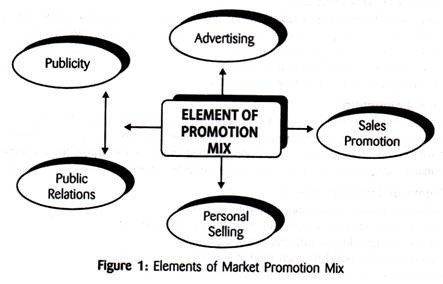
Sales Promotion Techniques
 by
by Sales promotion is an important tool of promotion which supplements personal selling and advertising efforts. According to American Marketing Association, “Sales promotion includes those marketing activities, other than personal selling, advertising, and publicity, that stimulate consumer purchasing and dealer effectiveness, such as displays, shows and expositions, demonstration, and various non-recurrent selling efforts not in the ordinary routine.”
Sales promotion includes techniques like free samples, premium on sale, sales and dealer incentives, contests, fairs and exhibitions, public relations activities, etc. Sales promotions are those activities, other than advertising and personal selling that stimulate market demand for products. The basic purpose is to stimulate on the spot buying by prospective customers through short-term incentives. These incentives are essentially temporary and non-recurring in nature.
Sales promotion is different from personal selling which is persuasion of customers by the sales persons to buy certain products. It is also different from advertising. Except for advertising through direct mail, advertising deals with media owned and controlled by the firm itself.
Usually, sales promotion deals with non-recurring and non-routine methods in contrast to personal selling or advertising. As a matter of fact, sales promotion activities aim at supplementing and co-ordinating personal selling and advertising.
Sales promotion includes activities of non-routine nature to promote sales, e.g., distribution of samples, discount coupons, contests, display of goods, fairs and exhibitions, etc. But it does not include advertisement, publicity and personal selling.
Techniques of Slaes Promotion
- Distribution of Samples
Many big businessmen distribute free samples of their products to the selected people in order to popularise their products. Distribution of samples is popular in case of books, drugs, cosmetics, perfumes and other similar products. As the distribution of samples is very costly, this system is confined to those products of small value which have often repeated sales.
- Rebate or Price-Off Offer
In order to increase sale, many producers introduce price off offer to the customers. Under this, the product is offered at a price lower than the normal price. For example, during off season (winter), ceiling fans, coolers and refrigerators may be offered at 20 to 30% off price.
Rebate offer is given for a limited period only, for example, Coca cola offered 2 litre bottle at Rs. 35 only during winter 2009. Khadi Gram Udyog offers rebates on Khadi cloth and readymades to coincide with the month of Gandhi Jayanti every year.
- Partial Refund
A firm may use the strategy of refunding a part of the price paid by the customer on the production of some proof of purchase of its product. For instance, the buyer of two cakes of a branded soap may be refunded Rs. 5 on returning the empty packages to the dealer.
- Discount Coupons
A discount coupon is a certificate that entitles its holder to a specified saving on the purchase of a specified product. Coupons may be issued by the manufacturers either directly by mail through sales-force or through the dealers. The coupons are also issued through newspapers and magazines. The holders of coupons can go to the retailers and get the product at a cheaper price.
The retailers are reimbursed by the manufacturer for the value of coupon redeemed and also paid a small percentage to cover handling cost. But many retailers do not patronise this method because it involves financial and accounting problems for them.
- Packaged Premium
Under this, the seller offers premium to the buyer by way of supplying a gift along with the product or inside the product package. Premium on sales helps the salesman to make effective presentation, stimulate sale in a particular area, lead to enlistment of new customers and have the way for introducing new brands in the market. Premiums are generally given in the case of customer convenience goods such as packed tea leaves, blades, tooth-pastes and toilet soaps.
- Container Premium
Several firms use container premium to push the sale of their products. For instance, Taj Mahal tea leaves, Ariel detergent powder, Bournvita, Kissan jams, etc. are made available in special containers which could be reused in kitchens after the product has been consumed. The reusable containers for packaging often have special appeal to the consumers who don’t have to pay anything extra for the product.
- Contests
There may be consumers’ contests, salesman’s contests and dealers’ contests. Contests for salesman and dealers are intended for inducing them to devote greater efforts or for obtaining new sales idea in the task of sales promotion.
Contests for consumers may centre around writing a slogan on the product. Such slogan centres around the questions as to the liking of a customer for the product, or formulation of new advertising idea for the product. Such contests are held through radio, T.V., newspapers, magazines, etc.
- Public Relations
Public relations activities strive for creating a good image of the enterprise in the eyes of the customers and the society. These activities are not aimed at immediate demand creation. It is very common that big business enterprises convey their greetings and thanks to the people through newspapers and other media.
- Free Gift
The customer does not get any benefit at the time of purchase, rather he gets it through mail. For this he has to send the proof of purchase (e.g., cash memo and wrapper) to the manufacturer to claim the gift which might be a diary or book or any other item. The gift is sent by the manufacturer by mail or through courier.
- Exchange Offer
It means exchange of an old product with the new one after payment of the exchange price fixed by the manufacturer. Such offers are very common these days in case of electric irons, TVs, refrigerators, scooters, gas stoves, washing machines, etc.
- Product Combination or Gift
It refers to giving a free gift on purchase of a product. Generally, the free gift is related to the product but it is not necessary. For example, Mug free with Bournvita, Toothbrush free with Toothpaste, DVD free with TV, Vacuum cleaner free Fridge, etc.
- Instant Draws and Assured Gifts
Some sectors offer instant draws and assured gifts to their customers when they make purchases. The scheme may be like – “Scratch a card (or burst a cracker) and instantly win a car, A.C., fridge, T.V., computer or electric iron on the purchase of a T.V.”
- Full Finance @ 0%
Manufacturers of durables like bikes, T.V., A.C., etc. offer easy financing schemes even at 0% rate of interest e.g., “Pay Rs. 10,000 in cash and Rs. 30,000 in 12 equal instalments of 2,500 each by post-dated cheques and get a bike on the spot.” This tool of promotion misleads the customers and so should be avoided by the marketers.
Objectives of Sales Promotion
(i) It improves the performance of middlemen and acts as a supplement to advertising and personal selling.
(ii) It motivates sales force to give desire emphasis on new accounts, latent accounts, new products and new territories.
(iii) It increases sales and makes sales of slow moving products faster and stabilize fluctuating sales pattern.
(iv)It attracts channel members to participate in manufacturer promotion effort.
(v) Motivating the dealers to buy high volumes of products and push more of the brands that are on promotion.
(vi) Supporting and supplementing the advertising and personal selling efforts.
(vii) Making consumers to switch brands in favour of firm.
(viii) To overcome the seasonal fluctuation of products.
(ix) Inducing retailers to promote the brand by local advertising and POP display.
(x) Sales promotions motivate the salesmen to sell more and to sell the full line of products.
(xi) To reduce the perception of risk associated with the purchase of a product.
Need and Importance of Sales Promotion
Sales promotion acts as a bridge between advertising and personal selling. Due to the adversity of markets, the importance of sales promotion has increased tremendously. Sales promotion helps remove the consumer’s dissatisfaction about a particular product, manufacturer, and create brand-image in the minds of the consumers and the users.
Sales promotional devices are the only promotional devices available at the point-of-purchase. An advertising medium reaches the prospects at their homes, offices, etc. and may soon be forgotten. The sales promotional devices at the point-of-purchase stimulate the customers to make purchase promptly on the spot.
Business firms use promotional tools to achieve the following benefits:
(i) Attracting Attention
The first aim of sales promotion is to attract the attention of the prospective buyers and inform them about the availability, characteristics and uses of a particular product.
(ii) Highlighting Utility of Product
Promotion helps in letting the people know about the utility of the new products. It also tells them how the concerned products will be helpful in satisfying their specific demands.
(iii) Stimulation of Demand of New Product
Promotional activities are used to create interest in the new product and to persuade people to buy the same. This helps in launching the new product.
(iv) Product Differentiation
Promotion helps in differentiating a particular product of the firm from the competing products of other firms. A firm can also use data revealing how its product compares with the other products.
(v) Synergy in Promotional Activities
Sales promotion activities supplement personal selling and advertising efforts of the firm. They add to the overall effectiveness of the firm’s promotional activities.
(vi) Stabilisation of Sales Volume
In the modern age of competition, it is an important purpose of promotion to help in stabilising sales volume by reassuring the customers about the quality and price of the product. It is possible that a customer using a particular brand, may buy another because the other brand is promoted in an effective manner.
(vii) Performance Appraisal or Marketing Control
The management of a company can keep an effective check on the results achieved through sales promotion schemes, because it is in a position to analyse the costs incurred and the benefits derived.