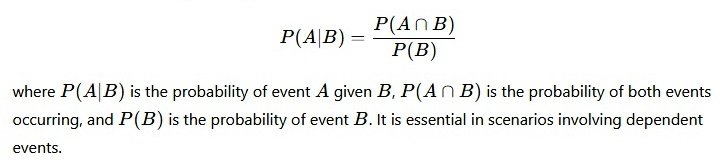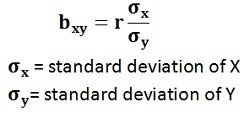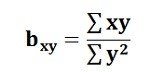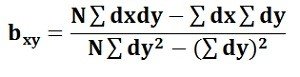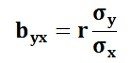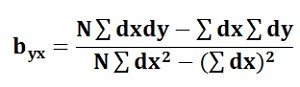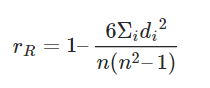Correlation and Regression
Correlation and regression are two important statistical tools used to study the relationship between variables. Both help managers analyze data and make informed business decisions. While correlation measures the degree and direction of relationship between variables, regression explains the cause-and-effect relationship and helps in prediction. Though closely related, their objectives and applications are different.
Correlation
The term correlation is a combination of two words ‘Co’ (together) and relation (connection) between two quantities. Correlation is when, at the time of study of two variables, it is observed that a unit change in one variable is retaliated by an equivalent change in another variable, i.e. direct or indirect. Or else the variables are said to be uncorrelated when the movement in one variable does not amount to any movement in another variable in a specific direction. It is a statistical technique that represents the strength of the connection between pairs of variables.
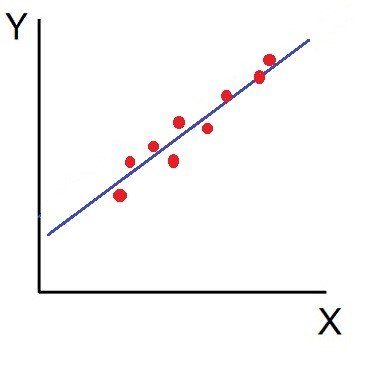
Correlation refers to a statistical measure that indicates the extent and direction of relationship between two variables. It shows whether variables move together or in opposite directions. Correlation is expressed numerically through the correlation coefficient (r), whose value lies between –1 and +1. A positive value indicates direct relationship, a negative value indicates inverse relationship, and zero indicates no relationship. Correlation does not indicate causation; it only measures association.
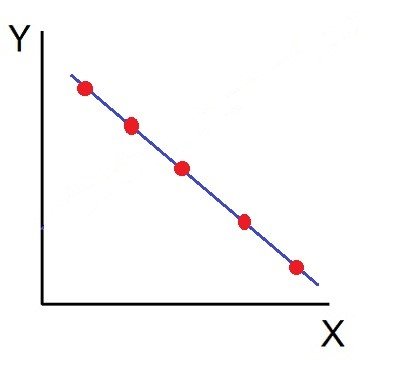
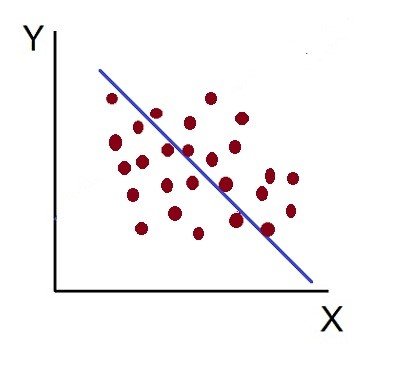
On the contrary, when the two variables move in different directions, in such a way that an increase in one variable will result in a decrease in another variable and vice versa, This situation is known as negative correlation. For instance: Price and demand of a product.
The measures of correlation are given as under:
- Karl Pearson’s Product-moment correlation coefficient
- Spearman’s rank correlation coefficient
- Scatter diagram
- Coefficient of concurrent deviations
Regression
Regression analysis is a statistical technique that establishes a functional or causal relationship between a dependent variable and one or more independent variables. It helps estimate or predict the value of one variable based on the known value of another. Regression provides a mathematical equation that explains how much change in the dependent variable is caused by changes in independent variables. It is widely used in forecasting and planning.
Differences Between Correlation and Regression
1. Meaning and Concept
Correlation and regression differ fundamentally in their basic meaning and conceptual approach. Correlation is a statistical measure that shows the degree and direction of relationship between two variables. It simply answers the question of whether variables are related and how strongly they move together. It does not explain why the relationship exists.
Regression, on the other hand, is a statistical technique that establishes a functional or causal relationship between variables. It explains how one variable (dependent) is affected by changes in another variable (independent). Regression goes beyond association and attempts to quantify the impact of one variable on another. Thus, while correlation is concerned with measuring association, regression focuses on explanation and prediction, making it more powerful for business decision-making.
2. Objective of Study
The objective of correlation is to determine whether a relationship exists between variables and to measure its strength and direction. It helps analysts understand patterns and tendencies in data. Correlation answers questions like: Are sales and advertising related? or Do income and consumption move together?
The objective of regression is to predict or estimate the value of one variable based on another. It is used when a business wants to forecast outcomes, such as predicting sales based on price or estimating costs based on output. Regression analysis provides a mathematical equation that can be used for planning, control, and forecasting. Hence, correlation is mainly descriptive in nature, while regression is both descriptive and predictive, making regression more suitable for managerial decision-making
3. Nature of Relationship
Correlation measures the degree of linear relationship between variables but does not indicate any cause-and-effect connection. Even if two variables are highly correlated, one may not necessarily cause changes in the other. For example, ice cream sales and electricity consumption may show correlation due to seasonal effects, not causation.
Regression, in contrast, assumes a cause-and-effect relationship between variables. It explains how changes in the independent variable bring about changes in the dependent variable. For instance, regression can estimate how much sales will increase due to a specific increase in advertising expenditure. Thus, correlation reflects association only, whereas regression attempts to establish dependence, which is crucial for business forecasting and strategic planning.
4. Treatment of Variables
In correlation, variables are treated symmetrically. There is no distinction between dependent and independent variables. The correlation between X and Y is the same as the correlation between Y and X. Both variables are given equal importance, and the analysis does not require identifying which variable influences the other.
In regression, variables are treated asymmetrically. One variable is clearly identified as the dependent variable, and the other(s) as independent variables. The entire analysis is based on explaining or predicting the dependent variable. For example, sales may depend on price and advertising. This clear distinction is essential for regression analysis, making it more suitable for practical business applications where cause-and-effect relationships are required.
5. Numerical Measure and Output
Correlation is expressed using a single numerical value, called the correlation coefficient (r). This value ranges from –1 to +1 and indicates only the strength and direction of relationship. A single figure summarizes the entire relationship, which makes correlation easy to compute and interpret but limited in analytical depth.
Regression produces regression equations, such as Y = a + bX, where coefficients show the magnitude of change in the dependent variable due to a unit change in the independent variable. These equations provide detailed quantitative insights and allow prediction. Therefore, while correlation provides a summary measure, regression offers a complete analytical model useful for forecasting and decision-making.
6. Symmetry and Direction
Correlation is symmetric in nature, meaning that correlation between X and Y is exactly the same as correlation between Y and X. There is no concept of direction of dependence in correlation analysis. This symmetry limits its usefulness in predictive analysis.
Regression is not symmetric. Regression of Y on X is different from regression of X on Y. Each regression equation serves a specific purpose depending on which variable is treated as dependent. This directional nature makes regression a powerful analytical tool. It helps managers decide which variable should be predicted and which variables should be used as predictors, making regression more practical for real-world business problems.
7. Use in Prediction and Forecasting
Correlation is not suitable for prediction. Although it indicates the existence of a relationship, it does not provide a mechanism to estimate future values. A high correlation does not necessarily mean accurate forecasting is possible.
Regression is specifically designed for prediction and forecasting. Using regression equations, businesses can estimate future sales, costs, profits, or demand based on known values of independent variables. This makes regression extremely valuable for planning, budgeting, and policy formulation. Thus, correlation is primarily exploratory, while regression is predictive and decision-oriented.
8. Practical Application in Business
Correlation is mainly used for preliminary analysis. It helps identify whether variables are related and whether further analysis is worthwhile. For example, before performing regression, managers often check correlation to see if a relationship exists.
Regression has direct practical applications in business, including sales forecasting, demand estimation, cost control, pricing decisions, and investment analysis. It provides a scientific basis for managerial decisions. Hence, correlation serves as a starting point in analysis, while regression forms the foundation of advanced quantitative decision-making in business.
Key Differences Between Correlation and Regression
| Aspect |
Correlation |
Regression |
| Meaning |
Correlation measures the degree and direction of relationship between two variables. |
Regression measures the functional and causal relationship between variables. |
| Nature |
It shows association only. |
It shows cause-and-effect relationship. |
| Objective |
To determine whether variables are related and how strongly. |
To predict or estimate the value of one variable from another. |
| Type of Relationship |
Indicates linear association only. |
Explains dependence of one variable on another. |
| Variables |
Does not distinguish between dependent and independent variables. |
Clearly distinguishes dependent and independent variables. |
| Direction of Influence |
No direction of influence is implied. |
Direction of influence is clearly defined. |
| Numerical Measure |
Expressed through a single value called correlation coefficient (r). |
Expressed through regression equations. |
| Range of Values |
Lies between –1 and +1. |
No fixed range for regression coefficients. |
| Symmetry |
Symmetric in nature (X with Y = Y with X). |
Asymmetric (Regression of Y on X ≠ X on Y). |
| Use in Prediction |
Not suitable for prediction. |
Specifically used for forecasting and prediction. |
| Number of Equations |
Only one coefficient is calculated. |
Two regression equations can be formed. |
| Dependency Assumption |
No assumption of dependency. |
Assumes dependency of one variable on another. |
| Effect of Change in Units |
Correlation coefficient is unit-free. |
Regression coefficients depend on measurement units. |
| Business Application |
Used mainly for preliminary analysis. |
Widely used for decision-making and planning. |
| Analytical Depth |
Provides limited analytical insight. |
Provides detailed quantitative analysis. |
 by
by