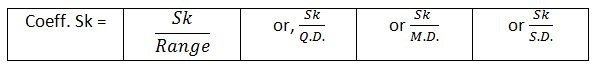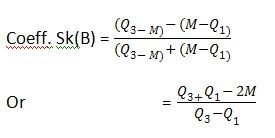Bill of Exchange
 by
by According to the Negotiable Instruments Act 1881, “A bill of exchange is defined as an instrument in writing containing an unconditional order, signed by the maker, directing a certain person to pay a certain sum of money only to, or to the order of a certain person or to the bearer of the instrument.”
Features of bill of exchange
- It is important to have a bill of exchange in writing
- It must contain a confirm order to make a payment and not just the request
- The order should not have any condition
- The bill of exchange amount should be definite
- Fixed date for the amount to be paid
- The bill must be signed by both the drawee and the drawer
- The amount stated on the bill should be paid on-demand or on the expiry of a fixed time
- The amount is paid to the beneficiary of the bill, specific person, or against a definite order
Types of Bill of Exchange
-
Documentary Bill
In this, the bill of exchange is supported by the relevant documents that confirm the genuineness of sale or transaction that took place between the seller and buyer.
-
Demand Bill
This bill is payable when it demanded. The bill does not have a fixed date of payment, therefore, the bill has to be cleared whenever presented.
-
Usance Bill
It is a time-bound bill which means the payment has to be made within the given time period and time.
-
Inland Bill
An Inland bill is payable only in one country and not in any other foreign country. This bill is opposite to foreign bill.
-
Clean Bill
This bill does not have any proof of a document, so the interest is comparatively higher than the other bills.
-
Foreign Bill
A bill that can be paid outside India is termed as a foreign bill. Two examples of a foreign bill are an export bill and import bill.
-
Accommodation Bill
A bill that is sponsored, drawn, accepted without any condition is known as an accommodation bill.
-
Trade Bill
This kind of bill is specially related only to trade.
-
Supply Bill
The bill that is withdrawn by the supplier or contractor from the government department is known as the supply bill.
Advantages of Bill of Exchange
- Legal Document: It is a legal document, and if the drawee fails to make the payment it will be easier for the drawer to recover the amount legally.
- Discounting Facility: The bill bearer has to wait till the due date of the bill to receive the payment and it from the bank before its due date.
- Endorsement Possible: This bill of exchange can be exchanged from one individual to another for the adjustment of the debt.
Parties of Bill of Exchange
A bill of exchange has three parties:
-
Drawer
- The drawer is the maker of a bill of exchange.
- The bill is signed by Drawer.
- A creditor who is entitled to receive payment from the debtor can draw a bill of exchange.
-
Drawee
- Drawee is the person upon whom the bill of exchange is drawn.
- Drawee is the debtor who has to pay the money to the drawer.
- He is also known as ‘Acceptor’.
-
Payee
- The payee is the person to whom payment has to be made.
- The payee may be the drawer himself or a third party.
Importance of Promissory note in Bill of Exchange
According to the Negotiable Instruments Act 1881, the meaning of promissory note is ‘an instrument in writing (not being a banknote or a currency note), containing an unconditional undertaking signed by the maker, to pay a certain sum of money only to or to the order of a certain person, or to the bearer of the instrument. However, according to the Reserve Bank of India Act, a promissory note payable to bearer is illegal. Therefore, a promissory note cannot be made payable to the bearer.’