Calculating interest rate is not at all a difficult method to understand. Knowing to calculate interest rate can solve a lot of wages problems and save money while taking investment decisions. There is an easy formula to calculate simple interest rates. If you are aware of your loan and interest amount you can pay, you can do the largest interest rate calculation for yourself.
Using the simple interest calculation formula, you can also see your interest payments in a year and calculate your annual percentage rate.
Here is the step by step guide to calculate the interest rate.
How to calculate interest rate?
Know the formula which can help you to calculate your interest rate.
Step 1
To calculate your interest rate, you need to know the interest formula I/Pt = r to get your rate. Here,
I = Interest amount paid in a specific time period (month, year etc.)
P = Principle amount (the money before interest)
t = Time period involved
r = Interest rate in decimal
You should remember this equation to calculate your basic interest rate.
Step 2
Once you put all the values required to calculate your interest rate, you will get your interest rate in decimal. Now, you need to convert the interest rate you got by multiplying it by 100. For example, a decimal like .11 will not help much while figuring out your interest rate. So, if you want to find your interest rate for .11, you have to multiply .11 with 100 (.11 x 100).
For this case, your interest rate will be (.11 x 100 = 11) 11%.
Step 3
Apart from this, you can also calculate your time period involved, principal amount and interest amount paid in a specific time period if you have other inputs available with you.
Calculate interest amount paid in a specific time period, I = Prt.
Calculate the principal amount, P = I/rt.
Calculate time period involved t = I/Pr.
Step 4
Most importantly, you have to make sure that your time period and interest rate are following the same parameter.
For example, on a loan, you want to find your monthly interest rate after one year. In this case, if you put t = 1, you will get the final interest rate as the interest rate per year. Whereas, if you want the monthly interest rate, you have to put the correct amount of time elapsed. Here, you can consider the time period like 12 months.
Please remember, your time period should be the same time amount as the interest paid. For example, if you’re calculating a year’s monthly interest payments then, it can be considered you’ve made 12 payments.
Also, you have to make sure that you check the time period (weekly, monthly, yearly etc.) when your interest is calculated with your bank.
Step 5
You can rely on online calculators to get interest rates for complex loans, such as mortgages. You should also know the interest rate of your loan when you sign up for it.
For fluctuating rates, sometimes it becomes difficult to determine what a certain rate means. So, it is better to use free online calculators by searching “variable APR interest calculator”, “mortgage interest calculator” etc.
Calculation of interest when rate of interest and cash price is given
- Where Cash Price, Interest Rate and Instalment are Given:
Illustration:
On 1st January 2003, A bought a television from a seller under Hire Purchase System, the cash price of which being Rs 10.450 as per the following terms:
(a) Rs 3,000 to be paid on signing the agreement.
(b) Balance to be paid in three equal installments of Rs 3,000 at the end of each year,
(c) The rate of interest charged by the seller is 10% per annum.
You are required to calculate the interest paid by the buyer to the seller each year.
Solution:

Note:
- there is no time gap between the signing of the agreement and the cash down payment of Rs 3,000 (1.1.2003). Hence no interest is calculated. The entire amount goes to reduce the cash price.
- The interest in the last installment is taken at the differential figure of Rs 285.50 (3,000 – 2,714.50).
(2) Where Cash Price and Installments are Given but Rate of Interest is Omitted:
Where the rate of interest is not given and only the cash price and the total payments under hire purchase installments are given, then the total interest paid is the difference between the cash price of the asset and the total amount paid as per the agreement. This interest amount is apportioned in the ratio of amount outstanding at the end of each period.
Illustration:
Mr. A bought a machine under hire purchase agreement, the cash price of the machine being Rs 18,000. As per the terms, the buyer has to pay Rs 4,000 on signing the agreement and the balance in four installments of Rs 4,000 each, payable at the end of each year. Calculate the interest chargeable at the end of each year.
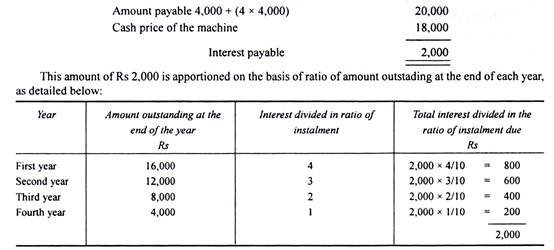
(3) Where installments and Rate of Interest are Given but Cash Value of the Asset is Omitted:
In certain problems, the cash price is not given. It is necessary that we must first find out the cash price and interest included in the installments. The asset account is to be debited with the actual price of the asset. Under such situations, i.e. in the absence of cash price, the interest is calculated from the last year.
It may be noted that the amount of interest goes on increasing from 3rd year to 2nd year, 2nd year to 1st year. Since the interest is included in the installments and by knowing the rate of interest, we can find out the cash price.
Thus:
Let the cash price outstanding be: Rs 100
Interest @ 10% on Rs 100 for a year: Rs 10
Installment paid at the end of the year 110
The interest on installment price = 10/110 or 1/11 as a ratio.
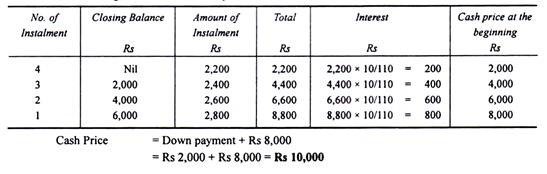
Illustration:
I buy a television on Hire Purchase System.
The terms of payment are as follows:
Rs 2,000 to be paid on signing the agreement;
Rs 2,800 at the end of the first year;
Rs 2,600 at the end of the second year;
Rs 2,400 at the end of the third year;
Rs 2,200 at the end of the fourth year.
If interest is charged at the rate of 10% p.a., what was the cash value of the television?
Solution:
(4) Calculation of Cash Price when Reference to Annuity Table, the Rate of Interest and Installments are Given:
Sometimes in the problem a reference to annuity table wherein present value of the annuity for a number of years at a certain rate of interest is given. In such cases the cash price is calculated by multiplying the amount of installment and adding the product to the initial payment.
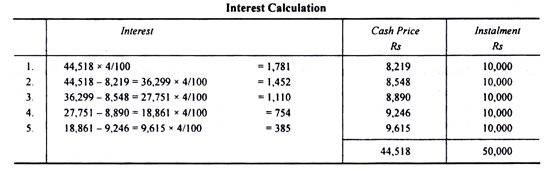
Illustration:
A agrees to purchase a machine from a seller under Hire Purchase System by annual installment of Rs 10,000 over a period of 5 years. The seller charges interest at 4% p.a. on yearly balance.
N.B. The present value of Re 1 p.a. for five years at 4% is Rs 4.4518. Find out the cash price of the machine.
Solution:
Installment Re 1 Present value = Rs 4.4518
Installment = Rs 10,000 Present value = Rs 4.4518 x 10,000 = Rs 44,518
Credit: https://www.yourarticlelibrary.com/accounting/hire-purchase/how-to-calculate-interest-4-cases-hire-purchase/51175
Like this:
Like Loading...
 by
by 





