 by
by A distributed database is basically a database that is not limited to one system, it is spread over different sites, i.e, on multiple computers or over a network of computers. A distributed database system is located on various sited that don’t share physical components. This maybe required when a particular database needs to be accessed by various users globally. It needs to be managed such that for the users it looks like one single database.
A distributed database is a collection of multiple interconnected databases, which are spread physically across various locations that communicate via a computer network.
Goals of Distributed Database system
The concept of distributed database was built with a goal to improve:
(i) Reliability
In distributed database system, if one system fails down or stops working for some time another system can complete the task.
(ii) Availability
In distributed database system reliability can be achieved even if sever fails down. Another system is available to serve the client request.
(iii) Performance
Performance can be achieved by distributing database over different locations. So the databases are available to every location which is easy to maintain.
Advantages of Distributed Databases
Following are the advantages of distributed databases over centralized databases.
(i) Modular Development
If the system needs to be expanded to new locations or new units, in centralized database systems, the action requires substantial efforts and disruption in the existing functioning. However, in distributed databases, the work simply requires adding new computers and local data to the new site and finally connecting them to the distributed system, with no interruption in current functions.
(ii) More Reliable
In case of database failures, the total system of centralized databases comes to a halt. However, in distributed systems, when a component fails, the functioning of the system continues may be at a reduced performance. Hence DDBMS is more reliable.
(iii) Better Response
If data is distributed in an efficient manner, then user requests can be met from local data itself, thus providing faster response. On the other hand, in centralized systems, all queries have to pass through the central computer for processing, which increases the response time.
(iv) Lower Communication Cost
In distributed database systems, if data is located locally where it is mostly used, then the communication costs for data manipulation can be minimized. This is not feasible in centralized systems.
Types of distributed database System
The two types of distributed systems are as follows:
- Homogeneous distributed databases system
In a homogeneous database, all different sites store database identically. The operating system, database management system and the data structures used – all are same at all sites. Hence, they’re easy to manage.

Example: Consider that we have three departments using Oracle-9i for DBMS. If some changes are made in one department then, it would update the other department also.
- Heterogeneous Database
In a heterogeneous distributed database, different sites can use different schema and software that can lead to problems in query processing and transactions. Also, a particular site might be completely unaware of the other sites. Different computers may use a different operating system, different database application. They may even use different data models for the database. Hence, translations are required for different sites to communicate.
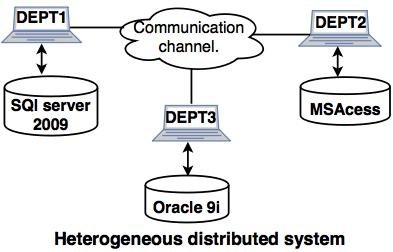
Example: In the following diagram, different DBMS software are accessible to each other using ODBC and JDBC.
Distributed Data Storage
There are 2 ways in which data can be stored on different sites. These are:
- Replication
In this approach, the entire relation is stored redundantly at 2 or more sites. If the entire database is available at all sites, it is a fully redundant database. Hence, in replication, systems maintain copies of data.
This is advantageous as it increases the availability of data at different sites. Also, now query requests can be processed in parallel.
However, it has certain disadvantages as well. Data needs to be constantly updated. Any change made at one site needs to be recorded at every site that relation is stored or else it may lead to inconsistency. This is a lot of overhead. Also, concurrency control becomes way more complex as concurrent access now needs to be checked over a number of sites.
- Fragmentation
In this approach, the relations are fragmented (i.e., they’re divided into smaller parts) and each of the fragments is stored in different sites where they’re required. It must be made sure that the fragments are such that they can be used to reconstruct the original relation (i.e, there isn’t any loss of data).
Fragmentation is advantageous as it doesn’t create copies of data, consistency is not a problem.
Fragmentation of relations can be done in two ways:
- Horizontal fragmentation – Splitting by rows – The relation is fragmented into groups of tuples so that each tuple is assigned to at least one fragment.
- Vertical fragmentation – Splitting by columns – The schema of the relation is divided into smaller schemas. Each fragment must contain a common candidate key so as to ensure lossless join.