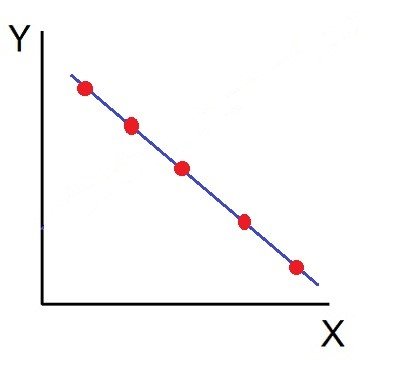
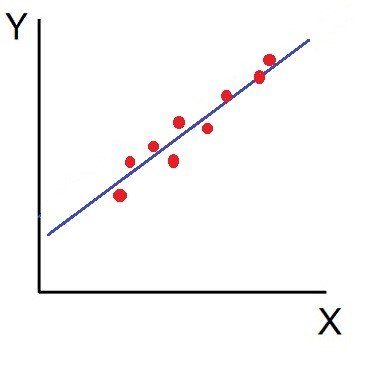
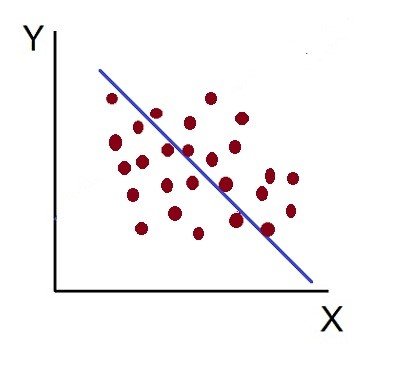
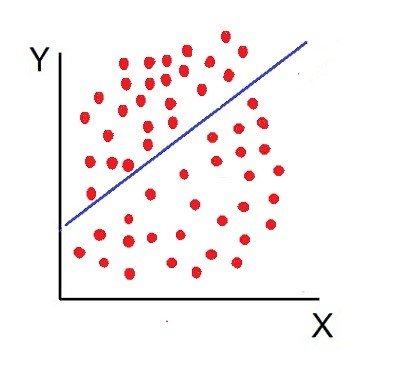
Statistics is a branch of mathematics focused on collecting, organizing, analyzing, interpreting, and presenting data. It provides tools for understanding patterns, trends, and relationships within datasets. Key concepts include descriptive statistics, which summarize data using measures like mean, median, and standard deviation, and inferential statistics, which draw conclusions about a population based on sample data. Techniques such as probability theory, hypothesis testing, regression analysis, and variance analysis are central to statistical methods. Statistics are widely applied in business, science, and social sciences to make informed decisions, forecast trends, and validate research findings. It bridges raw data and actionable insights.
Definitions of Statistics:
A.L. Bowley defines, “Statistics may be called the science of counting”. At another place he defines, “Statistics may be called the science of averages”. Both these definitions are narrow and throw light only on one aspect of Statistics.
According to King, “The science of statistics is the method of judging collective, natural or social, phenomenon from the results obtained from the analysis or enumeration or collection of estimates”.
Horace Secrist has given an exhaustive definition of the term satistics in the plural sense. According to him:
“By statistics we mean aggregates of facts affected to a marked extent by a multiplicity of causes numerically expressed, enumerated or estimated according to reasonable standards of accuracy collected in a systematic manner for a pre-determined purpose and placed in relation to each other”.
Features of Statistics:
Statistics deals with numerical data. It focuses on collecting, organizing, and analyzing numerical information to derive meaningful insights. Qualitative data is also analyzed by converting it into quantifiable terms, such as percentages or frequencies, to facilitate statistical analysis.
Statistics emphasize collective data rather than individual values. A single data point is insufficient for analysis; meaningful conclusions require a dataset with multiple observations to identify patterns or trends.
Statistics consider multiple variables simultaneously. This feature allows it to study relationships, correlations, and interactions between various factors, providing a holistic view of the phenomenon under study.
Statistics aim to present precise and accurate findings. Mathematical formulas, probabilistic models, and inferential techniques ensure reliability and reduce the impact of random errors or biases.
Statistics employs inductive reasoning to generalize findings from a sample to a broader population. By analyzing sample data, statistics infer conclusions that can predict or explain population behavior. This feature is particularly crucial in fields like market research and public health.
Statistics is versatile and applicable in numerous fields, such as business, economics, medicine, engineering, and social sciences. It supports decision-making, risk assessment, and policy formulation. For example, businesses use statistics for market analysis, while medical researchers use it to evaluate treatment effectiveness.
Objectives of Statistics:
- Data Collection and Organization
One of the primary objectives of statistics is to collect reliable data systematically. It aims to gather accurate and comprehensive information about a phenomenon to ensure a solid foundation for analysis. Once collected, statistics organize data into structured formats such as tables, charts, and graphs, making it easier to interpret and understand.
Statistics condense large datasets into manageable and meaningful summaries. Techniques like calculating averages, medians, percentages, and standard deviations provide a clear picture of the data’s central tendency, dispersion, and distribution. This helps identify key trends and patterns at a glance.
Statistics aims to study relationships and associations between variables. Through tools like correlation analysis and regression models, it identifies connections and influences among factors, offering insights into causation and dependency in various contexts, such as business, economics, and healthcare.
A key objective is to use historical and current data to forecast future trends. Statistical methods like time series analysis, probability models, and predictive analytics help anticipate events and outcomes, aiding in decision-making and strategic planning.
Statistics provide a scientific basis for making informed decisions. By quantifying uncertainty and evaluating risks, statistical tools guide individuals and organizations in choosing the best course of action, whether it involves investments, policy-making, or operational improvements.
Statistics validate or refute hypotheses through structured experiments and observations. Techniques like hypothesis testing, significance testing, and analysis of variance (ANOVA) ensure conclusions are based on empirical evidence rather than assumptions or biases.
Functions of Statistics:
The first function of statistics is to gather reliable and relevant data systematically. This involves designing surveys, experiments, and observational studies to ensure accuracy and comprehensiveness. Proper data collection is critical for effective analysis and decision-making.
Statistics organizes raw data into structured and understandable formats. It uses tools such as tables, charts, graphs, and diagrams to present data clearly. This function transforms complex datasets into visual representations, making it easier to comprehend and analyze.
Condensing large datasets into concise measures is a vital statistical function. Descriptive statistics, such as averages (mean, median, mode) and measures of dispersion (range, variance, standard deviation), summarize data and highlight key patterns or trends.
Statistics analyze relationships between variables to uncover associations, correlations, and causations. Techniques like correlation analysis, regression models, and cross-tabulations help understand how variables influence one another, supporting in-depth insights.
Statistics enable forecasting future outcomes based on historical data. Predictive models, probability distributions, and time series analysis allow organizations to anticipate trends, prepare for uncertainties, and optimize strategies.
One of the most practical functions of statistics is guiding decision-making processes. Statistical tools quantify uncertainty and evaluate risks, helping individuals and organizations choose the most effective solutions in areas like business, healthcare, and governance.
Importance of Statistics:
Statistics is essential for making informed decisions in business, government, healthcare, and personal life. It helps evaluate alternatives, quantify risks, and choose the best course of action. For instance, businesses use statistical models to optimize operations, while governments rely on it for policy-making.
In the modern era, data is abundant, and statistics provides the tools to analyze it effectively. By summarizing and interpreting data, statistics reveal patterns, trends, and relationships that might not be apparent otherwise. These insights are critical for strategic planning and innovation.
Statistics enables accurate predictions about future events by analyzing historical and current data. In fields like economics, weather forecasting, and healthcare, statistical models anticipate trends and guide proactive measures.
Statistical methods are foundational in scientific research. They validate hypotheses, measure variability, and ensure the reliability of conclusions. Fields such as medicine, social sciences, and engineering heavily depend on statistical tools for advancements and discoveries.
Industries use statistics for quality assurance and process improvement. Techniques like Six Sigma and control charts monitor and enhance production processes, ensuring product quality and customer satisfaction.
Statistics is indispensable in studying social and economic issues such as unemployment, poverty, population growth, and market dynamics. It helps policymakers and researchers analyze complex phenomena, develop solutions, and measure their impact.
Limitations of Statistics:
Statistics focuses primarily on numerical data and struggles with subjective or qualitative information, such as emotions, opinions, or behaviors. Although qualitative data can sometimes be quantified, the essence or context of such data may be lost in the process.
Statistical results can be easily misinterpreted if the underlying methods, data collection, or analysis are flawed. Misuse of statistical tools, intentional or otherwise, can lead to misleading conclusions, making it essential to use statistics with caution and expertise.
Statistics often require a sufficiently large dataset for reliable analysis. Small or biased samples can lead to inaccurate results, reducing the validity and reliability of conclusions drawn from such data.
Statistics can identify correlations or associations between variables but cannot establish causation. For example, a statistical analysis might show that ice cream sales and drowning incidents are related, but it cannot confirm that one causes the other without further investigation.
Statistics rely heavily on the accuracy and relevance of data. If the data collected is incomplete, inaccurate, or biased, the resulting statistical analysis will also be flawed, leading to unreliable conclusions.
Statistical findings are often based on historical data and may not account for changes in external factors, such as economic shifts, technological advancements, or evolving societal norms. This limitation can reduce the applicability of statistical models over time.
Statistics deal with facts and figures, often ignoring human values, emotions, and ethical considerations. For instance, a purely statistical analysis might prioritize cost savings over employee welfare or customer satisfaction.
Like this:
Like Loading...
 by
by