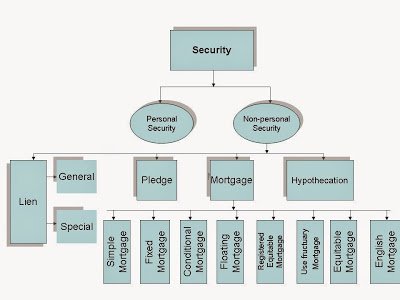
The following are the rights of a collecting banker:
- The banker should present the cheque to the paying banker for encashment within a reasonable time. What is reasonable time depends upon the facts of each case. As per the prevailing practice, the collecting banker should present the cheques received for collection from customers at least by the following or next day after he receives it. Any undue delay in collection would render the banker liable to the customer for any loss the latter may suffer on account of the delay.
- If the cheque presented in clearing is realized, then the proceeds of the realized cheque should be credited to the account of the customer without any delay.
- In case the cheque sent for collection is dishonoured by the drawee bank, the collecting bank should return the cheque to the customer within a reasonable time so as to enable the customer to recover the amount of the cheque from parties liable thereto. If he fails to send the notice of dishonour of the cheque to the customer within a reasonable time and the customer suffers a loss as a consequence of the omission to send the notice, the collecting banker becomes liable to compensate the customer.
The Following are the rights and duties of a collecting banker.
- Cheque crossed generally be paid only to banker
- A cheque crossed specially should be paid only to through banker
- Second special crossing in favour of the banker
- A banker cannot ignore the crossing
Liabilities of Paying Banker
- Proper Form
A banker should see whether the cheque is in the proper form. That means the cheque should be in the manner prescribed under the provisions of the commercial code. It should not contain any condition.
- Open or Crossed Cheque
The most important precaution that a banker should take is about crossed cheques. A banker has to verify whether the cheque is open or crossed. He should not pay cash across the counter in respect of crossed cheques. If the cheque is a crossed one, he should see whether it is a general crossing or special crossing. If it is a general crossing, the holder must be asked to present the cheque through some banker. It should be paid to a banker. If the cheque bears a special crossing, the banker should pay only the bank whose name is mentioned in then crossing. If it is an open cheque, a banker can pay cash to the payee or the holder across the counter. If the banker pays against the instructions as indicated above, he is liable to pay the amount to the true owner for any loss sustained. Further, a banker loses statutory protection in case of forged endorsement.
For example, Madras Bank Ltd. Vs South India Match Factory Ltd., a cheque was issued by a purchaser in favour of the official liquidator of a company towards the purchase price of certain properties. The bank paid the amount of the crossed cheque to the liquidator across the counter. The liquidator mis-appropriated the amount. The court held that the banker committed breach of statutory duty and was negligent in paying direct to the liquidator over the counter and hence, was not entitled to legal protection.
If it is a ‘Not Negotiable’ crossing, the paying banker has to verify the genuineness of all the endorsements. If it is an ‘Account Payee’ crossing, the banker can credit the account of the payee named in the cheque and not that of any other person.
- Place of Presentment of Cheque
A banker can honour the cheques provided it is presented with that branch of the bank where the drawer has an account. If the cheque is presented at another branch of the same bank, it should not be honoured unless special arrangements are made by the customer in advance. The reasons are:
- A banker undertakes to pay cheques only at the branch where the account is kept.
- The specimen signature of the customer will be with the office of the bank at which he has an account.
- It is not possible for other branches to know that the customer has adequate balance to meet the cheque.
Bank of India Vs Official Liquidator: In this case, it was held that if customer has an account in a bank which has several branches, the branches at which he has no account are justified in refusing to honour his cheques.
- Date of the Cheque
The paying banker has to see the date of the cheque. It must be properly dated. It should not be either a post-dated cheque or a stale-cheque. If a cheque carries a future date, it becomes a post-dated cheque. If the cheque is presented on the date mentioned in the cheque, the banker need not have any objection to honour it. If the banker honours a cheque before the date mentioned in the cheque, he loses statutory protection. If the drawer dies or becomes insolvent or countermands payment before the date of the cheque, he will lose the amount. The undated cheques are usually not honoured.
A stale cheque is one which has been in circulation for an unreasonably long period.
The custom of bankers in this respect varies. Generally, a cheque is considered stale when it has been in circulation for more than six months. Banker does not honour such cheques. However, banker may get confirmation from the drawer and honour cheques which are in circulation for a long time. So, verification of date is very important.
- Mutilated Cheque
The banker should be careful when mutilated cheques are presented for payment. A cheque is said to be mutilated when it has been cut or torn, or when a part of it is missing. Mutilation may be either accidental or intentional.
If it is accidental, the banker should get the drawer’s confirmation before honouring it. If it is intentional, he should refuse payment. The cheque is to be returned with a remark ‘Mutilated cheque’ or ‘Mutilation Requires Confirmation’. In Scholey Vs Ramsbottom, the banker was held liable for wrong payment of a cheque which was dirty and bore visible marks of mutilation.”
- Words and Figures
The amount of the cheque should be expressed in words, or in words and figures, which should agree with each other. When the amount in words and figures differ, the banker should refuse payment. However, there is difference between the amount in words and figures; the amount in words is the amount payable. If the banker returns the cheque, he should make a remark ‘amount in words and figures differ.
- Alterations and Overwritings
The banker should see whether there is any alteration or over-writing on the cheque. If there is any alteration, it should be confirmed by the drawer by putting his full signature. The banker should not pay a cheque containing material alteration without confirmation by the drawer. The banker is expected to exercise reasonable care for the detection of such alterations.
Otherwise, he has to take risk. Material alterations make a cheque void.
- Proper Endorsements
Cheques must be properly endorsed. In the case of bearer cheque, endorsement is not necessary legally. In the case of an order cheque, endorsement is necessary. A bearer cheque always remains a bearer cheque. The paying banker should examine all the endorsements on the cheque before making payment. They must be regular. But it is not the duty of the paying banker to verify the genuineness of the endorsements, unless the cheque bears ‘Not-Negotiable’ crossing. He is not expected to know the signatures of all payees. So he gets statutory protection in case of forged endorsements. In India, even in the case of bearer cheques, bankers insist on endorsement though it is not required.
- Sufficiency of Funds
The banker should see whether the credit balance in the customer’s account is sufficient to pay the cheque or not. If there is an overdraft agreement, he should see that the limit is not exceeded. The banker should not make part-payment of the cheque. He should pay either full amount or refuse payment. In case of insufficiency of funds, the banker should return the cheque with the remark ‘No Funds’ or ‘Not Sufficient Funds’.
- Verification of Drawer’s Signature
The banker takes specimen signatures of his customers’ at the time of opening the account. He should compare the drawer’s signature on the cheque with the specimen signature of the customer. He should carefully examine the signature to find out whether the drawer’s signature is forged or not. If there is any difference or doubt, he should not honour the cheque. He should get the confirmation of the drawer. If there is forgery and there is negligence on the part of the banker to detect the same, there is no protection to the banker.
Liabilities of Collecting Banker
- Due Care and Diligence in the Collection of Cheques
The collecting banker is bound to show due care and diligence in the collection of cheques presented to him.
In case a cheque is entrusted with the banker for collection, he is expected to show it to the drawee banker within a reasonable time. A cheque is not presented for payment within a reasonable time of its issue, and the drawer or person in whose account it is drawn had the right, at the time when presentment ought to have been made, as between himself and the banker, to have the cheque paid and suffers actual damage, through the delay, he is discharged to the extent of such damage, that is to say, to the extent to which such drawer or person is a creditor of the banker to a large amount than he would have been if such cheque had been paid.
In case a collecting banker does not present the cheque for collection through proper channel within a reasonable time, the customer may suffer loss. In case the collecting banker and the paying banker are in the same bank or where the collecting branch is also the drawee branch, in such a case the collecting banker should present the cheque by the next day. In case the cheque is drawn on a bank in another place, it should be presented on the day after receipt.
- Serving Notice of Dishonor
When the cheque is dishonored, the collecting banker is bound to give notice of the same to his customer within a reasonable time. It may be noted here, when a cheque is returned for confirmation of endorsement, notice must be sent to his customer. If he fails to give such a notice, the collecting banker will be liable to the customer for any loss that the customer may have suffered on account of such failure.
Whereas a cheque is returned by the drawee banker for confirmation of endorsement, it is not called dishonor. But in such a case, notice must be given to the customer. In the absence of such a notice, if the cheque is returned for the second time and the customer suffers a loss, the collecting banker will be liable for the loss.
- Agent for Collection
In case a cheque is drawn on a place where the banker is not a member of the ‘clearing-house’, he may employ another banker who is a member of the clearing-house for the purpose of collecting the cheque. In such a case the banker becomes a substituted agent. An agent, holding an express or implied authority to name another person to act in the business of the agency has accordingly named another person, such a person is a substituted agent. Such an agent shall be taken as the agent of a principal for such part of the work as is entrusted to him.
- Remittance of Proceeds to the Customer
In case a collecting banker has realized the cheque, he should pay the proceeds to the customer as per his (customer’s) direction. Generally, the amount is credited to the account of the customer on the customer’s request in writing; the proceeds may be remitted to him by a demand draft. In such circumstances, if the customer gives instructions to his banker, the draft may be forwarded. By doing so, the relationship between principal and agent comes to an end and the new relationship between debtor and creditor will begin.
- Collection of Bills of Exchange
There is no legal obligation for a banker to collect the bills of exchange for its customer. But, generally, bank gives such facility to its customers. In collection of bills, a banker should examine the title of the depositor as the statutory protection.
Thus, the collecting banker must examine very carefully the title of his customer towards the bill. In case a new customer comes, the banker should extend this facility to him with a trusted reference.
From the above discussion, there is no doubt to say that the banker is acting as a mere agent for collection and not in the capacity of a banker. If the customer allows his banker to use the collecting money for its own purpose at present and to repay an equivalent amount on a fixed date in future the contract between the banker and the customer will come to an end.

Like this:
Like Loading...
 by
by